Download presentation
Presentation is loading. Please wait.

1
Bases de Datos Biologicas ¿Que es una base de datos? ¿Que tipos de datos hay disponibles? ¿que es el esquema Genbank ? ¿Como es una entrada de datos en una BD biologica? ¿Como se usan?

2
¿Que es una base de datos? Es una colección de datos que tiene que ser: –estructurada –Buscable –regular updates –links y referencias a otras colecciones de datos

3
Tipos de Bases de Datos NAR 2004 Genome scale databases have proliferated Traditional sequence databases are now a small part Databases around new specific data types are emerging Pathway and disease orientated databases are emerging

4
Bioinformatics Information Space Bioinformatics Information Space July 17, 1999 Nucleotide sequences:4,456,822 Protein sequences: 706,862 3D structures: 9,780 Human Unigene Clusters: 75,832 Maps and Complete Genomes: 10,870 Different species node: 52,889 dbSNP 6,377 RefGenes 515 human contigs > 250 kb 341 (4.9MB) PubMed records: 10,372,886 OMIM records: 10,695
 PubMed records: 10,372,886 OMIM records: 10,695")
5
Nucleotide records36,653,899 Protein sequences4,436,362 3D structures19,640 Interactions & complexes52,385 Human Unigene Cluster118,517 Maps and Complete Genomes6,948 Different taxonomy Nodes283,121 Human dbSNP13,179,601 Human RefSeq records22,079 bp in Human Contigs > 5,000 kb (116) 2,487,920,000 PubMed records12,570,540 OMIM records15,138 Bioinformatics Information Space Bioinformatics Information Space Februar 10, 2004
 2,487,920,000 PubMed records12,570,540 OMIM records15,138 Bioinformatics Information Space Bioinformatics Information Space Februar 10, 2004")
6
http://nar.oupjournals.org/content/vol31/issue2/

7
Biological databases Like any other database –Data organization for optimal analysis Data is of different types –Raw data (DNA, RNA, protein sequences) –Curated data (DNA, RNA and protein annotated sequences and structures, expression data)
 –Curated data (DNA, RNA and protein annotated sequences and structures, expression data)")
8
Tipos de Bases de Datos NAR 2004

9
DatabasesDatabases Information system Query system Storage System Data

10
DatabasesDatabases Information system Query system Storage System Data GenBank flat file PDB file Interaction Record Title of a book Book

11
DatabasesDatabases Information system Query system Storage System Data Boxes Oracle MySQL PC binary files Unix text files Bookshelves

12
DatabasesDatabases Information system Query system Storage System Data A List you look at A catalogue indexed files SQL grep

13
Google Entrez SRS DatabasesDatabases Information system Query system Storage System Data

14
Tipos de organización de Bases de datos Flat file databases (flat DBMS) –Simple, restrictive, table Hierarchical databases (hierarchical DBMS) –Simple, restrictive, tables Relational databases (RDBMS) –Complex,versatile, tables Object-oriented databases (ODBMS) –Complex, versatile, objects
 –Simple, restrictive, table Hierarchical databases (hierarchical DBMS) –Simple, restrictive, tables Relational databases (RDBMS) –Complex,versatile, tables Object-oriented databases (ODBMS) –Complex, versatile, objects")
15
DBMSDBMS Internal organization –Controls speed and flexibility A unity of programs that –Store –Extract –Modify Database StoreExtractModify USER(S)
")
16
Advanced Databases Relational Databases –Contain data and relationships Version Control Consistency enforcement Multi-author/multi-user with security

17
Data warehouse Periodically, one imports data from databases and store it (locally) in the data warehouse. Now a local database can be created, containing for instance protein family data (sequence, structure, function and pathway/process data integrated with the gene expression and other experimental data). Disadvantage: expensive, intensive, needs to be updated. Advantage: easy control of integrated data-mining pipeline.
. Disadvantage: expensive, intensive, needs to be updated. Advantage: easy control of integrated data-mining pipeline..")
18
Storage in databases Data analysis Bioinformatics Global efforts to collect: sequence data structure data protein expression profiles functional data genes expression profies…... Colecciones de datos en el mundo

19
EBI GenBank DDBJ EMBL EMBL Entrez SRS getentry NIG CIB NCBI NIH Submissions Updates Submissions Updates Submissions Updates Information is mirrored daily between DDBJ, GenBank and EMBL.

20
Databases Primary (archival) –GenBank/EMBL/DDBJ –UniProt –PDB –Medline (PubMed) –BIND Secondary (curated) –RefSeq –Taxon –UniProt –OMIM –SGD
 –GenBank/EMBL/DDBJ –UniProt –PDB –Medline (PubMed) –BIND Secondary (curated) –RefSeq –Taxon –UniProt –OMIM –SGD")
21
DDBJ Genbank HIVbase VECTOR EMBL GenPep RepBase IMGT TREMBL ESTs BD Acidos nucléicos

22
PIR HIVbase Swissprot PDB PROSITE BLOCKS Enzyme TREMBL GenPept BD de proteinas

23
DNA Sequence Files Formats –Information content Conversion/Usage

24
Genbank ASN1 FASTA GCG IG(Intelligenetics) Text Others!!! Common formats
 Text Others!!! Common formats")
25
FASTAFASTA >gi|1345098|gb|U30791.1|PCU30791 TGAATTCTAAATTTTATATTTCTAATTGCATTTTATATTTTTGATAA TACTAGATTTATTCCTGGAAACTTAAATTAGTTATTTTAAGTTATG GGATGTTGTTTTTCTGCTACATATAACCAAGATACACTTCGTTCC AA

26
What is GenBank? GenBank is the NIH genetic sequence database of all publicly available DNA and derived protein sequences, with annotations describing the biological information these records contain. http://www.ncbi.nlm.nih.gov/Genbank/GenbankOverview.html Benson et al., 2004, Nucleic Acids Res. 32:D23-D26

27
GenBank Flat File (GBFF) LOCUS MUSNGH 1803 bp mRNA ROD 29-AUG-1997 DEFINITION Mouse neuroblastoma and rat glioma hybridoma cell line NG108-15 cell TA20 mRNA, complete cds. ACCESSION D25291 NID g1850791 KEYWORDS neurite extension activity; growth arrest; TA20. SOURCE Murinae gen. sp. mouse neuroblastma-rat glioma hybridoma cell_line:NG108-15 cDNA to mRNA. ORGANISM Murinae gen. sp. Eukaryotae; mitochondrial eukaryotes; Metazoa; Chordata; Vertebrata; Mammalia; Eutheria; Rodentia; Sciurognathi; Muridae; Murinae. REFERENCE 1 (sites) AUTHORS Tohda,C., Nagai,S., Tohda,M. and Nomura,Y. TITLE A novel factor, TA20, involved in neuronal differentiation: cDNA cloning and expression JOURNAL Neurosci. Res. 23 (1), 21-27 (1995) MEDLINE 96064354 REFERENCE 3 (bases 1 to 1803) AUTHORS Tohda,C. TITLE Direct Submission JOURNAL Submitted (18-NOV-1993) to the DDBJ/EMBL/GenBank databases. Chihiro Tohda, Toyama Medical and Pharmaceutical University, Research Institute for Wakan-yaku, Analytical Research Center for Ethnomedicines; 2630 Sugitani, Toyama, Toyama 930-01, Japan (E-mail:CHIHIRO@ms.toyama-mpu.ac.jp, Tel:+81-764-34-2281(ex.2841), Fax:+81-764-34-5057) COMMENT On Feb 26, 1997 this sequence version replaced gi:793764. FEATURES Location/Qualifiers source 1..1803 /organism="Murinae gen. sp." /note="source origin of sequence, either mouse or rat, has not been identified" /db_xref="taxon:39108" /cell_line="NG108-15" /cell_type="mouse neuroblastma-rat glioma hybridoma" misc_signal 156..163 /note="AP-2 binding site" GC_signal 647..655 /note="Sp1 binding site" TATA_signal 694..701 gene 748..1311 /gene="TA20" CDS 748..1311 /gene="TA20" /function="neurite extensiion activity and growth arrest effect" /codon_start=1 /db_xref="PID:d1005516" /db_xref="PID:g793765" /translation="MMKLWVPSRSLPNSPNHYRSFLSHTLHIRYNNSLFISNTHLSRR KLRVTNPIYTRKRSLNIFYLLIPSCRTRLILWIIYIYRNLKHWSTSTVRSHSHSIYRL RPSMRTNIILRCHSYYKPPISHPIYWNNPSRMNLRGLLSRQSHLDPILRFPLHLTIYY RGPSNRSPPLPPRNRIKQPNRIKLRCR" polyA_site 1803 BASE COUNT 507 a 458 c 311 g 527 t ORIGIN 1 tcagtttttt tttttttttt tttttttttt tttttttttt tttttttttg ttgattcatg 61 tccgtttaca tttggtaagt tcacaggcct cagtcaacac aattggactg ctcaggaaat 121 cctccttggt gaccgcagta tacttggcct atgaacccaa gccacctatg gctaggtagg 181 agaagctcaa ctgtagggct gactttggaa gagaatgcac atggctgtat cgacatttca 241 catggtggac ctctggccag agtcagcagg ccgagggttc tcttccgggc tgctccctca 301 ctgcttgact ctgcgtcagt gcgtccatac tgtgggcgga cgttattgct atttgccttc 361 cattctgtac ggcattgcct ccatttagct ggagagggac agagcctggt tctctagggc 421 gtttccattg gggcctggtg acaatccaaa agatgagggc tccaaacacc agaatcagaa 481 ggcccagcgt atttgtaaaa acaccttctg gtgggaatga atggtacagg ggcgtttcag 541 gacaaagaac agcttttctg tcactcccat gagaaccgtc gcaatcactg ttccgaagag 601 gaggagtcca gaatacacgt gtatgggcat gacgattgcc cggagagagg cggagcccat 661 ggaagcagaa agacgaaaaa cacacccatt atttaaaatt attaaccact cattcattga 721 cctacctgcc ccatccaaca tttcatcatg atgaaacttt gggtcccttc taggagtctg 781 cctaatagtc caaatcatta caggtctttt cttagccata cactacacat cagatacaat 841 aacagccttt tcatcagtaa cacacatttg tcgagacgta aattacgggt gactaatccg 901 atatatacac gcaaacggag cctcaatatt ttttatttgc ttattccttc atgtcggacg 961 aggcttatat tatggatcat atacatttat agaaacctga aacattggag tacttctact 1021 gttcgcagtc atagccacag catttatagg ctacgtcctt ccatgaggac aaatatcatt 1081 ctgaggtgcc acagttatta caaacctcct atcagccatc ccatatattg gaacaaccct 1141 agtcgaatga atttgagggg gcttctcagt agacaaagcc accttgaccc gattcttcgc 1201 tttccacttc atcttaccat ttattatcgc ggccctagca atcgttcacc tcctcttcct 1261 ccacgaaaca ggatcaaaca acccaacagg attaaactca gatgcagata aaattccatt 1321 tcacccctac tatacatcaa agatatccta ggtatcctaa tcatattctt aattctcata 1381 accctagtat tatttttccc agacatacta ggagacccag acaactacat accagctaat 1441 ccactaaaca ccccacccca tattaaaccc gaatgatatt tcctatttgc atacgccatt 1501 ctacgctcaa tccccaataa actaggaggt gtcctagcct taatcttatc tatcctaatt 1561 ttagccctaa tacctttcct tcatacctca aagcaacgaa gcctaatatt ccgcccaatc 1621 acacaaattt tgtactgaat cctagtagcc aacctactta tcttaacctg aattgggggc 1681 caaccagtag acacccattt attatcattg gccaactagc ctccatctca tacttctcaa 1741 tcatcttaat tcttatacca atctcaggaa ttatcgaaga caaaatacta aaattatatc 1801 cat // Features (AA seq) DNA Sequence Header Title Taxonomy Citation
 AUTHORS Tohda,C., Nagai,S., Tohda,M. and Nomura,Y. TITLE A novel factor, TA20, involved in neuronal differentiation: cDNA cloning and expression JOURNAL Neurosci. Res. 23 (1), (1995) MEDLINE REFERENCE 3 (bases 1 to 1803) AUTHORS Tohda,C. TITLE Direct Submission JOURNAL Submitted (18-NOV-1993) to the DDBJ/EMBL/GenBank databases. Chihiro Tohda, Toyama Medical and Pharmaceutical University, Research Institute for Wakan-yaku, Analytical Research Center for Ethnomedicines; 2630 Sugitani, Toyama, Toyama , Japan Tel: (ex.2841), Fax: ) COMMENT On Feb 26, 1997 this sequence version replaced gi: FEATURES Location/Qualifiers source /organism= Murinae gen. sp. /note= source origin of sequence, either mouse or rat, has not been identified /db_xref= taxon:39108 /cell_line= NG /cell_type= mouse neuroblastma-rat glioma hybridoma misc_signal /note= AP-2 binding site GC_signal /note= Sp1 binding site TATA_signal gene /gene= TA20 CDS /gene= TA20 /function= neurite extensiion activity and growth arrest effect /codon_start=1 /db_xref= PID:d /db_xref= PID:g /translation= MMKLWVPSRSLPNSPNHYRSFLSHTLHIRYNNSLFISNTHLSRR KLRVTNPIYTRKRSLNIFYLLIPSCRTRLILWIIYIYRNLKHWSTSTVRSHSHSIYRL RPSMRTNIILRCHSYYKPPISHPIYWNNPSRMNLRGLLSRQSHLDPILRFPLHLTIYY RGPSNRSPPLPPRNRIKQPNRIKLRCR polyA_site 1803 BASE COUNT 507 a 458 c 311 g 527 t ORIGIN 1 tcagtttttt tttttttttt tttttttttt tttttttttt tttttttttg ttgattcatg 61 tccgtttaca tttggtaagt tcacaggcct cagtcaacac aattggactg ctcaggaaat 121 cctccttggt gaccgcagta tacttggcct atgaacccaa gccacctatg gctaggtagg 181 agaagctcaa ctgtagggct gactttggaa gagaatgcac atggctgtat cgacatttca 241 catggtggac ctctggccag agtcagcagg ccgagggttc tcttccgggc tgctccctca 301 ctgcttgact ctgcgtcagt gcgtccatac tgtgggcgga cgttattgct atttgccttc 361 cattctgtac ggcattgcct ccatttagct ggagagggac agagcctggt tctctagggc 421 gtttccattg gggcctggtg acaatccaaa agatgagggc tccaaacacc agaatcagaa 481 ggcccagcgt atttgtaaaa acaccttctg gtgggaatga atggtacagg ggcgtttcag 541 gacaaagaac agcttttctg tcactcccat gagaaccgtc gcaatcactg ttccgaagag 601 gaggagtcca gaatacacgt gtatgggcat gacgattgcc cggagagagg cggagcccat 661 ggaagcagaa agacgaaaaa cacacccatt atttaaaatt attaaccact cattcattga 721 cctacctgcc ccatccaaca tttcatcatg atgaaacttt gggtcccttc taggagtctg 781 cctaatagtc caaatcatta caggtctttt cttagccata cactacacat cagatacaat 841 aacagccttt tcatcagtaa cacacatttg tcgagacgta aattacgggt gactaatccg 901 atatatacac gcaaacggag cctcaatatt ttttatttgc ttattccttc atgtcggacg 961 aggcttatat tatggatcat atacatttat agaaacctga aacattggag tacttctact 1021 gttcgcagtc atagccacag catttatagg ctacgtcctt ccatgaggac aaatatcatt 1081 ctgaggtgcc acagttatta caaacctcct atcagccatc ccatatattg gaacaaccct 1141 agtcgaatga atttgagggg gcttctcagt agacaaagcc accttgaccc gattcttcgc 1201 tttccacttc atcttaccat ttattatcgc ggccctagca atcgttcacc tcctcttcct 1261 ccacgaaaca ggatcaaaca acccaacagg attaaactca gatgcagata aaattccatt 1321 tcacccctac tatacatcaa agatatccta ggtatcctaa tcatattctt aattctcata 1381 accctagtat tatttttccc agacatacta ggagacccag acaactacat accagctaat 1441 ccactaaaca ccccacccca tattaaaccc gaatgatatt tcctatttgc atacgccatt 1501 ctacgctcaa tccccaataa actaggaggt gtcctagcct taatcttatc tatcctaatt 1561 ttagccctaa tacctttcct tcatacctca aagcaacgaa gcctaatatt ccgcccaatc 1621 acacaaattt tgtactgaat cctagtagcc aacctactta tcttaacctg aattgggggc 1681 caaccagtag acacccattt attatcattg gccaactagc ctccatctca tacttctcaa 1741 tcatcttaat tcttatacca atctcaggaa ttatcgaaga caaaatacta aaattatatc 1801 cat // Features (AA seq) DNA Sequence Header Title Taxonomy Citation.")
28
Example: Growthfactor, implicated in parkinson syndrome LOCUS AF053749 1943 bp DNA PRI 09-JUL-1999 DEFINITION Homo sapiens glial cell line-derived neurotrophic factor (GDNF) gene, 5' flanking sequence and exon 1. ACCESSION AF053749 NID g5430697 VERSION AF053749.1 GI:5430697 KEYWORDS. SOURCE human. ORGANISM Homo sapiens Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Homo. REFERENCE 1 (bases 1 to 1943) AUTHORS Baecker,P.A., Lee,W.H., Verity,A.N., Eglen,R.M. and Johnson,R.M. TITLE Characterization of a promoter for the human glial cell line-derived neurotrophic factor gene JOURNAL Brain Res. Mol. Brain Res. 69 (2), 209-222 (1999) MEDLINE 99296655 REFERENCE 2 (bases 1 to 1943) AUTHORS Baecker,P.A., Lee,W.H., Verity,A.N., Eglen,R.M. and Johnson,R.M. TITLE Direct Submission JOURNAL Submitted (16-MAR-1998) Molecular and Cellular Biochemistry, Roche Bioscience, 3401 Hillview Avenue, Palo Alto, CA 94304, USA ….. Genebank entry
 AUTHORS Baecker,P.A., Lee,W.H., Verity,A.N., Eglen,R.M. and Johnson,R.M. TITLE Characterization of a promoter for the human glial cell line-derived neurotrophic factor gene JOURNAL Brain Res. Mol. Brain Res. 69 (2), (1999) MEDLINE REFERENCE 2 (bases 1 to 1943) AUTHORS Baecker,P.A., Lee,W.H., Verity,A.N., Eglen,R.M. and Johnson,R.M. TITLE Direct Submission JOURNAL Submitted (16-MAR-1998) Molecular and Cellular Biochemistry, Roche Bioscience, 3401 Hillview Avenue, Palo Alto, CA 94304, USA ….. Genebank entry.")
29
FEATURES Location/Qualifiers source 1..1943 /organism="Homo sapiens" /db_xref="taxon:9606" /chromosome="5" /map="5p12-p13.1" gene 1..>1943 /gene="GDNF" misc_feature 1..1643 /gene="GDNF" /note="5' flanking region" mRNA 1644..>1817 /gene="GDNF" /product="glial cell line-derived neurotrophic factor" 5'UTR 1644..>1817 /gene="GDNF" exon 1644..1817 /gene="GDNF" /number=1 BASE COUNT 356 a 662 c 576 g 349 t ORIGIN GAATTCAGGT CCAATGGCTT CCGGAAAACA GGTTTCTGCT TAGCAAAGAC ATGCCCTATT 60 TAGTACATTA TTTTAGAGGT ACAGCCAATT CCATGCCCCA TGTGAATGAA ATGTATTTAT 120 GGTTATAGCC ATGCACAGGG TGTGTAAGGA CTTGCCCTCC TCCTGTCCTC TACAAAAGAA 180 GGCTCAGGCA GCTTCTGGTG GTGAACTAAC CAACAAAAGG AATGCCCAGA AGGTCTCACC 240 TCTCCCATCC ACAGAGCTCT GGAATGGGGG CCGGGCCCCT GATCGCTGGA AACTCAGCAT 300 CCAAGTGGGC GCTTGCTGAA GTTTCCCATC TGCATTTTCG AAAATCTGGA TAAAAGCAGG 360 TTTAGCTCAA CCTCCCCTAA CCCGTTCCTG ATAAAGTGAT CTTACGCCTC TGGAATTGGG 420 …... Example: Growthfactor, implicated in parkinson syndrome

30
Genbank divisions PRI: primate sequences ROD: rodent sequences MAM: other mammalian sequences VRT: other vertbrate sequences INV: invertebrate sequences PLN: plant, fungal and algal sequences BCT: bacterial sequences VRL: viral sequences PHG: bacteriophage sequences SYN: synthetic sequences UNA: unannotated sequences EST: expressed sequence tags PAT: patent sequences STS: sequence tag sites GSS: genome survey sequences HTC: high throughput cDNA sequences HTG: high throughput genomic sequences

31
Features FEATURES Location/Qualifiers source 1..1234 /organism ="Pneumocystis carinii f. sp. carinii“ /strain="Form 6“ /note="450 kb chromosome" /db_xref="taxon:38081“ 5'UTR 1..90 gene 91..1155 /gene="pcg1"

32
CDS CDS91..1155 /gene="pcg1” /note="G-protein alpha subunit" /codon_start=1 /product="guanosine nucleotide binding protein alpha subunit" /protein_id="AAC49295.1" /db_xref="PID:g1345099" /db_xref="GI:1345099" /translation="MGCCFSATYNQDTLRSKEIE SYLRQEQEHACHEAKILLLGAGES…. Critical Evidence??

33
What’s Missing in DNA sequence files? Expression data Variation Curation/referee system limited EC or other standard bio-links Auto-update links to other information Specific clone information –Plasmid construction

34
What’s missing in protein files? Evidence that the protein exists –MOST ARE INFERRED from DNA (DNA protein links are not truly dynamic) EC links to metabolism/regulation/structure –Not uniformly done (see NoEc.gb.txt) Uniform description of modifications Cellular location
 EC links to metabolism/regulation/structure –Not uniformly done (see NoEc.gb.txt) Uniform description of modifications Cellular location.")
35
Types of files in GenBank From one-gene investigators –Often a very well annotated cDNA –A genomic segment from an new invertebrate –A mitochondria or virus From population/phylogenetic analysis –rRNA amplicon from environmental sampling From Genome Centers: –Gene expression: Expressed Sequence Tags (ESTs) Full Length Insert cDNA –Genome sequencing projects WGS HTG CON
 Full Length Insert cDNA –Genome sequencing projects WGS HTG CON")
36
UniProtUniProt New protein sequence database that is the result of a merge from SWISS-PROT and PIR. It will be the annotated curated protein sequence database. Data in UniProt is primarily derived from coding sequence annotations in EMBL (GenBank/DDBJ) nucleic acid sequence data. UniProt is a Flat-File database just like EMBL and GenBank Flat-File format is SwissProt-like, or EMBL-like
 nucleic acid sequence data. UniProt is a Flat-File database just like EMBL and GenBank Flat-File format is SwissProt-like, or EMBL-like.")
37
Swiss-ProtSwiss-Prot ID CYS3_YEAST STANDARD; PRT; 393 AA. AC P31373; DT 01-JUL-1993 (REL. 26, CREATED) DE CYSTATHIONINE GAMMA-LYASE (EC 4.4.1.1) (GAMMA-CYSTATHIONASE). GN CYS3 OR CYI1 OR STR1 OR YAL012W OR FUN35. OS TAXONOMY OC SACCHAROMYCETACEAE; SACCHAROMYCES. RX CITATION CC -!- CATALYTIC ACTIVITY: L-CYSTATHIONINE + H(2)O = L-CYSTEINE + CC NH(3) + 2-OXOBUTANOATE. CC -!- COFACTOR: PYRIDOXAL PHOSPHATE. CC -!- PATHWAY: FINAL STEP IN THE TRANS-SULFURATION PATHWAY SYNTHESIZING CC L-CYSTEINE FROM L-METHIONINE. CC -!- SUBUNIT: HOMOTETRAMER. CC -!- SUBCELLULAR LOCATION: CYTOPLASMIC. CC -!- SIMILARITY: BELONGS TO THE TRANS-SULFURATION ENZYMES FAMILY. CC -------------------------------------------------------------------------- CC DISCLAMOR CC -------------------------------------------------------------------------- DR DATABASE cross-reference KW CYSTEINE BIOSYNTHESIS; LYASE; PYRIDOXAL PHOSPHATE. FT INIT_MET 0 0 FT BINDING 203 203 PYRIDOXAL PHOSPHATE (BY SIMILARITY). SQ SEQUENCE 393 AA; 42411 MW; 55BA2771 CRC32; TLQESDKFAT KAIHAGEHVD VHGSVIEPIS LSTTFKQSSP ANPIGTYEYS RSQNPNRENL ERAVAALENA QYGLAFSSGS ATTATILQSL PQGSHAVSIG DVYGGTHRYF TKVANAHGVE TSFTNDLLND LPQLIKENTK LVWIETPTNP TLKVTDIQKV ADLIKKHAAG QDVILVVDNT FLSPYISNPL NFGADIVVHS ATKYINGHSD VVLGVLATNN KPLYERLQFL QNAIGAIPSP FDAWLTHRGL KTLHLRVRQA ALSANKIAEF LAADKENVVA VNYPGLKTHP NYDVVLKQHR DALGGGMISF RIKGGAEAAS KFASSTRLFT LAESLGGIES LLEVPAVMTH GGIPKEAREA SGVFDDLVRI SVGIEDTDDL LEDIKQALKQ ATN // ID CYS3_YEAST STANDARD; PRT; 393 AA. AC P31373; DT 01-JUL-1993 (REL. 26, CREATED) DT 01-JUL-1993 (REL. 26, LAST SEQUENCE UPDATE) DT 01-NOV-1995 (REL. 32, LAST ANNOTATION UPDATE) DE CYSTATHIONINE GAMMA-LYASE (EC 4.4.1.1) (GAMMA-CYSTATHIONASE). GN CYS3 OR CYI1 OR STR1 OR YAL012W OR FUN35. OS SACCHAROMYCES CEREVISIAE (BAKER'S YEAST). OC EUKARYOTA; FUNGI; ASCOMYCOTA; HEMIASCOMYCETES; SACCHAROMYCETALES; OC SACCHAROMYCETACEAE; SACCHAROMYCES. RN [1] RP SEQUENCE FROM N.A., AND PARTIAL SEQUENCE. RX MEDLINE; 92250430. [NCBI, ExPASy, Israel, Japan] RA ONO B.-I., TANAKA K., NAITO K., HEIKE C., SHINODA S., YAMAMOTO S., RA OHMORI S., OSHIMA T., TOH-E A.; RT "Cloning and characterization of the CYS3 (CYI1) gene of RT Saccharomyces cerevisiae."; RL J. BACTERIOL. 174:3339-3347(1992). RN [2] RP SEQUENCE FROM N.A., AND CHARACTERIZATION. RC STRAIN=DBY939; RX MEDLINE; 93328685. [NCBI, ExPASy, Israel, Japan] RA YAMAGATA S., D'ANDREA R.J., FUJISAKI S., ISAJI M., NAKAMURA K.; RT "Cloning and bacterial expression of the CYS3 gene encoding RT cystathionine gamma-lyase of Saccharomyces cerevisiae and the RT physicochemical and enzymatic properties of the protein."; RL J. BACTERIOL. 175:4800-4808(1993). RN [3] RP SEQUENCE FROM N.A. RC STRAIN=S288C / AB972; RX MEDLINE; 93289814. [NCBI, ExPASy, Israel, Japan] RA BARTON A.B., KABACK D.B., CLARK M.W., KENG T., OUELLETTE B.F.F., RA STORMS R.K., ZENG B., ZHONG W.W., FORTIN N., DELANEY S., BUSSEY H.; RT "Physical localization of yeast CYS3, a gene whose product resembles RT the rat gamma-cystathionase and Escherichia coli cystathionine gamma- RT synthase enzymes."; RL YEAST 9:363-369(1993). RN [4] RP SEQUENCE FROM N.A. RC STRAIN=S288C / AB972; RX MEDLINE; 93209532. [NCBI, ExPASy, Israel, Japan] RA OUELLETTE B.F.F., CLARK M.W., KENG T., STORMS R.K., ZHONG W.W., RA ZENG B., FORTIN N., DELANEY S., BARTON A.B., KABACK D.B., BUSSEY H.; RT "Sequencing of chromosome I from Saccharomyces cerevisiae: analysis RT of a 32 kb region between the LTE1 and SPO7 genes."; RL GENOME 36:32-42(1993). RN [5] RP SEQUENCE OF 1-18, AND CHARACTERIZATION. RX MEDLINE; 93289817. [NCBI, ExPASy, Israel, Japan] RA ONO B.-I., ISHII N., NAITO K., MIYOSHI S.-I., SHINODA S., YAMAMOTO S., RA OHMORI S.; RT "Cystathionine gamma-lyase of Saccharomyces cerevisiae: structural RT gene and cystathionine gamma-synthase activity."; RL YEAST 9:389-397(1993). CC -!- CATALYTIC ACTIVITY: L-CYSTATHIONINE + H(2)O = L-CYSTEINE + CC NH(3) + 2-OXOBUTANOATE. CC -!- COFACTOR: PYRIDOXAL PHOSPHATE. CC -!- PATHWAY: FINAL STEP IN THE TRANS-SULFURATION PATHWAY SYNTHESIZING CC L-CYSTEINE FROM L-METHIONINE. CC -!- SUBUNIT: HOMOTETRAMER. CC -!- SUBCELLULAR LOCATION: CYTOPLASMIC. CC -!- SIMILARITY: BELONGS TO THE TRANS-SULFURATION ENZYMES FAMILY. CC -------------------------------------------------------------------------- CC This SWISS-PROT entry is copyright. It is produced through a collaboration CC between the Swiss Institute of Bioinformatics and the EMBL outstation - CC the European Bioinformatics Institute. There are no restrictions on its CC use by non-profit institutions as long as its content is in no way CC modified and this statement is not removed. Usage by and for commercial CC entities requires a license agreement (See http://www.isb-sib.ch/announce/ CC or send an email to license@isb-sib.ch). CC -------------------------------------------------------------------------- DR EMBL; L05146; AAC04945.1; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR EMBL; L04459; AAA85217.1; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR EMBL; D14135; BAA03190.1; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR PIR; S31228; S31228. DR YEPD; 5280; -. DR SGD; L0000470; CYS3. [SGD / YPD] DR PFAM; PF01053; Cys_Met_Meta_PP; 1. DR PROSITE; PS00868; CYS_MET_METAB_PP; 1. DR DOMO; P31373. DR PRODOM [Domain structure / List of seq. sharing at least 1 domain] DR PROTOMAP; P31373. DR PRESAGE; P31373. DR SWISS-2DPAGE; GET REGION ON 2D PAGE. KW CYSTEINE BIOSYNTHESIS; LYASE; PYRIDOXAL PHOSPHATE. FT INIT_MET 0 0 FT BINDING 203 203 PYRIDOXAL PHOSPHATE (BY SIMILARITY). SQ SEQUENCE 393 AA; 42411 MW; 55BA2771 CRC32; TLQESDKFAT KAIHAGEHVD VHGSVIEPIS LSTTFKQSSP ANPIGTYEYS RSQNPNRENL ERAVAALENA QYGLAFSSGS ATTATILQSL PQGSHAVSIG DVYGGTHRYF TKVANAHGVE TSFTNDLLND LPQLIKENTK LVWIETPTNP TLKVTDIQKV ADLIKKHAAG QDVILVVDNT FLSPYISNPL NFGADIVVHS ATKYINGHSD VVLGVLATNN KPLYERLQFL QNAIGAIPSP FDAWLTHRGL KTLHLRVRQA ALSANKIAEF LAADKENVVA VNYPGLKTHP NYDVVLKQHR DALGGGMISF RIKGGAEAAS KFASSTRLFT LAESLGGIES LLEVPAVMTH GGIPKEAREA SGVFDDLVRI SVGIEDTDDL LEDIKQALKQ ATN //
 DE CYSTATHIONINE GAMMA-LYASE (EC ) (GAMMA-CYSTATHIONASE). GN CYS3 OR CYI1 OR STR1 OR YAL012W OR FUN35. OS TAXONOMY OC SACCHAROMYCETACEAE; SACCHAROMYCES. RX CITATION CC -!- CATALYTIC ACTIVITY: L-CYSTATHIONINE + H(2)O = L-CYSTEINE + CC NH(3) + 2-OXOBUTANOATE. CC -!- COFACTOR: PYRIDOXAL PHOSPHATE. CC -!- PATHWAY: FINAL STEP IN THE TRANS-SULFURATION PATHWAY SYNTHESIZING CC L-CYSTEINE FROM L-METHIONINE. CC -!- SUBUNIT: HOMOTETRAMER. CC -!- SUBCELLULAR LOCATION: CYTOPLASMIC. CC -!- SIMILARITY: BELONGS TO THE TRANS-SULFURATION ENZYMES FAMILY. CC CC DISCLAMOR CC DR DATABASE cross-reference KW CYSTEINE BIOSYNTHESIS; LYASE; PYRIDOXAL PHOSPHATE. FT INIT_MET 0 0 FT BINDING PYRIDOXAL PHOSPHATE (BY SIMILARITY). SQ SEQUENCE 393 AA; MW; 55BA2771 CRC32; TLQESDKFAT KAIHAGEHVD VHGSVIEPIS LSTTFKQSSP ANPIGTYEYS RSQNPNRENL ERAVAALENA QYGLAFSSGS ATTATILQSL PQGSHAVSIG DVYGGTHRYF TKVANAHGVE TSFTNDLLND LPQLIKENTK LVWIETPTNP TLKVTDIQKV ADLIKKHAAG QDVILVVDNT FLSPYISNPL NFGADIVVHS ATKYINGHSD VVLGVLATNN KPLYERLQFL QNAIGAIPSP FDAWLTHRGL KTLHLRVRQA ALSANKIAEF LAADKENVVA VNYPGLKTHP NYDVVLKQHR DALGGGMISF RIKGGAEAAS KFASSTRLFT LAESLGGIES LLEVPAVMTH GGIPKEAREA SGVFDDLVRI SVGIEDTDDL LEDIKQALKQ ATN // ID CYS3_YEAST STANDARD; PRT; 393 AA. AC P31373; DT 01-JUL-1993 (REL. 26, CREATED) DT 01-JUL-1993 (REL. 26, LAST SEQUENCE UPDATE) DT 01-NOV-1995 (REL. 32, LAST ANNOTATION UPDATE) DE CYSTATHIONINE GAMMA-LYASE (EC ) (GAMMA-CYSTATHIONASE). GN CYS3 OR CYI1 OR STR1 OR YAL012W OR FUN35. OS SACCHAROMYCES CEREVISIAE (BAKER S YEAST). OC EUKARYOTA; FUNGI; ASCOMYCOTA; HEMIASCOMYCETES; SACCHAROMYCETALES; OC SACCHAROMYCETACEAE; SACCHAROMYCES. RN [1] RP SEQUENCE FROM N.A., AND PARTIAL SEQUENCE. RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA ONO B.-I., TANAKA K., NAITO K., HEIKE C., SHINODA S., YAMAMOTO S., RA OHMORI S., OSHIMA T., TOH-E A.; RT Cloning and characterization of the CYS3 (CYI1) gene of RT Saccharomyces cerevisiae. ; RL J. BACTERIOL. 174: (1992). RN [2] RP SEQUENCE FROM N.A., AND CHARACTERIZATION. RC STRAIN=DBY939; RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA YAMAGATA S., D ANDREA R.J., FUJISAKI S., ISAJI M., NAKAMURA K.; RT Cloning and bacterial expression of the CYS3 gene encoding RT cystathionine gamma-lyase of Saccharomyces cerevisiae and the RT physicochemical and enzymatic properties of the protein. ; RL J. BACTERIOL. 175: (1993). RN [3] RP SEQUENCE FROM N.A. RC STRAIN=S288C / AB972; RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA BARTON A.B., KABACK D.B., CLARK M.W., KENG T., OUELLETTE B.F.F., RA STORMS R.K., ZENG B., ZHONG W.W., FORTIN N., DELANEY S., BUSSEY H.; RT Physical localization of yeast CYS3, a gene whose product resembles RT the rat gamma-cystathionase and Escherichia coli cystathionine gamma- RT synthase enzymes. ; RL YEAST 9: (1993). RN [4] RP SEQUENCE FROM N.A. RC STRAIN=S288C / AB972; RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA OUELLETTE B.F.F., CLARK M.W., KENG T., STORMS R.K., ZHONG W.W., RA ZENG B., FORTIN N., DELANEY S., BARTON A.B., KABACK D.B., BUSSEY H.; RT Sequencing of chromosome I from Saccharomyces cerevisiae: analysis RT of a 32 kb region between the LTE1 and SPO7 genes. ; RL GENOME 36:32-42(1993). RN [5] RP SEQUENCE OF 1-18, AND CHARACTERIZATION. RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA ONO B.-I., ISHII N., NAITO K., MIYOSHI S.-I., SHINODA S., YAMAMOTO S., RA OHMORI S.; RT Cystathionine gamma-lyase of Saccharomyces cerevisiae: structural RT gene and cystathionine gamma-synthase activity. ; RL YEAST 9: (1993). CC -!- CATALYTIC ACTIVITY: L-CYSTATHIONINE + H(2)O = L-CYSTEINE + CC NH(3) + 2-OXOBUTANOATE. CC -!- COFACTOR: PYRIDOXAL PHOSPHATE. CC -!- PATHWAY: FINAL STEP IN THE TRANS-SULFURATION PATHWAY SYNTHESIZING CC L-CYSTEINE FROM L-METHIONINE. CC -!- SUBUNIT: HOMOTETRAMER. CC -!- SUBCELLULAR LOCATION: CYTOPLASMIC. CC -!- SIMILARITY: BELONGS TO THE TRANS-SULFURATION ENZYMES FAMILY. CC CC This SWISS-PROT entry is copyright. It is produced through a collaboration CC between the Swiss Institute of Bioinformatics and the EMBL outstation - CC the European Bioinformatics Institute. There are no restrictions on its CC use by non-profit institutions as long as its content is in no way CC modified and this statement is not removed. Usage by and for commercial CC entities requires a license agreement (See CC or send an to CC DR EMBL; L05146; AAC ; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR EMBL; L04459; AAA ; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR EMBL; D14135; BAA ; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR PIR; S31228; S DR YEPD; 5280; -. DR SGD; L ; CYS3. [SGD / YPD] DR PFAM; PF01053; Cys_Met_Meta_PP; 1. DR PROSITE; PS00868; CYS_MET_METAB_PP; 1. DR DOMO; P DR PRODOM [Domain structure / List of seq. sharing at least 1 domain] DR PROTOMAP; P DR PRESAGE; P DR SWISS-2DPAGE; GET REGION ON 2D PAGE. KW CYSTEINE BIOSYNTHESIS; LYASE; PYRIDOXAL PHOSPHATE. FT INIT_MET 0 0 FT BINDING PYRIDOXAL PHOSPHATE (BY SIMILARITY). SQ SEQUENCE 393 AA; MW; 55BA2771 CRC32; TLQESDKFAT KAIHAGEHVD VHGSVIEPIS LSTTFKQSSP ANPIGTYEYS RSQNPNRENL ERAVAALENA QYGLAFSSGS ATTATILQSL PQGSHAVSIG DVYGGTHRYF TKVANAHGVE TSFTNDLLND LPQLIKENTK LVWIETPTNP TLKVTDIQKV ADLIKKHAAG QDVILVVDNT FLSPYISNPL NFGADIVVHS ATKYINGHSD VVLGVLATNN KPLYERLQFL QNAIGAIPSP FDAWLTHRGL KTLHLRVRQA ALSANKIAEF LAADKENVVA VNYPGLKTHP NYDVVLKQHR DALGGGMISF RIKGGAEAAS KFASSTRLFT LAESLGGIES LLEVPAVMTH GGIPKEAREA SGVFDDLVRI SVGIEDTDDL LEDIKQALKQ ATN //.")
38
Swiss-ProtSwiss-Prot

39
PAT Patent EST Expressed Sequence Tags STS Sequence Tagged Site GSS Genome Survey Sequence HTG High Throughput Genome (unfinished) HTC High throughput cDNA (unfinished) CON Contig assembly instructions ENV Environmental sampling methods Organismal divisions: BCTFUNINVMAMPHGPLN PRIRODSYNVRLVRT Functional Divisions
 HTC High throughput cDNA (unfinished) CON Contig assembly instructions ENV Environmental sampling methods Organismal divisions: BCTFUNINVMAMPHGPLN PRIRODSYNVRLVRT Functional Divisions")
40
SWISS-PROT incorporates: Function of the protein Post-translational modification Domains and sites. Secondary structure. Quaternary structure. Similarities to other proteins; Diseases associated with deficiencies in the protein Sequence conflicts, variants, etc. Swiss-ProtSwiss-Prot SWISS-PROT incorporates: Function of the protein Post-translational modification Domains and sites. Secondary structure. Quaternary structure. Similarities to other proteins; Diseases associated with deficiencies in the protein Sequence conflicts, variants, etc.

41
TREMBLTREMBL TrEMBL is a computer-annotated protein sequence database supplementing the SWISS-PROT Protein Sequence Data Bank. TrEMBL contains the translations of all coding sequences (CDS) present in the EMBL Nucleotide Sequence Database not yet integrated in SWISS- PROT. TrEMBL can be considered as a preliminary section of SWISS-PROT. For all TrEMBL entries which should finally be upgraded to the standard SWISS- PROT quality, SWISS-PROT accession numbers have been assigned.
 present in the EMBL Nucleotide Sequence Database not yet integrated in SWISS- PROT. TrEMBL can be considered as a preliminary section of SWISS-PROT. For all TrEMBL entries which should finally be upgraded to the standard SWISS- PROT quality, SWISS-PROT accession numbers have been assigned..")
42
PDBPDB Protein DataBase –Protein and NA 3D structures –Sequence present –YAFFF

43
HEADER LEUCINE ZIPPER 15-JUL-93 1DGC 1DGC 2 COMPND GCN4 LEUCINE ZIPPER COMPLEXED WITH SPECIFIC 1DGC 3 COMPND 2 ATF/CREB SITE DNA 1DGC 4 SOURCE GCN4: YEAST (SACCHAROMYCES CEREVISIAE); DNA: SYNTHETIC 1DGC 5 AUTHOR T.J.RICHMOND 1DGC 6 REVDAT 1 22-JUN-94 1DGC 0 1DGC 7 JRNL AUTH P.KONIG,T.J.RICHMOND 1DGC 8 JRNL TITL THE X-RAY STRUCTURE OF THE GCN4-BZIP BOUND TO 1DGC 9 JRNL TITL 2 ATF/CREB SITE DNA SHOWS THE COMPLEX DEPENDS ON DNA 1DGC 10 JRNL TITL 3 FLEXIBILITY 1DGC 11 JRNL REF J.MOL.BIOL. V. 233 139 1993 1DGC 12 JRNL REFN ASTM JMOBAK UK ISSN 0022-2836 0070 1DGC 13 REMARK 1 1DGC 14 REMARK 2 1DGC 15 REMARK 2 RESOLUTION. 3.0 ANGSTROMS. 1DGC 16 REMARK 3 1DGC 17 REMARK 3 REFINEMENT. 1DGC 18 REMARK 3 PROGRAM X-PLOR 1DGC 19 REMARK 3 AUTHORS BRUNGER 1DGC 20 REMARK 3 R VALUE 0.216 1DGC 21 REMARK 3 RMSD BOND DISTANCES 0.020 ANGSTROMS 1DGC 22 REMARK 3 RMSD BOND ANGLES 3.86 DEGREES 1DGC 23 REMARK 3 1DGC 24 REMARK 3 NUMBER OF REFLECTIONS 3296 1DGC 25 REMARK 3 RESOLUTION RANGE 10.0 - 3.0 ANGSTROMS 1DGC 26 REMARK 3 DATA CUTOFF 3.0 SIGMA(F) 1DGC 27 REMARK 3 PERCENT COMPLETION 98.2 1DGC 28 REMARK 3 1DGC 29 REMARK 3 NUMBER OF PROTEIN ATOMS 456 1DGC 30 REMARK 3 NUMBER OF NUCLEIC ACID ATOMS 386 1DGC 31 REMARK 4 1DGC 32 REMARK 4 GCN4: TRANSCRIPTIONAL ACTIVATOR OF GENES ENCODING FOR AMINO 1DGC 33 REMARK 4 ACID BIOSYNTHETIC ENZYMES. 1DGC 34 REMARK 5 1DGC 35 REMARK 5 AMINO ACIDS NUMBERING (RESIDUE NUMBER) CORRESPONDS TO THE 1DGC 36 REMARK 5 281 AMINO ACIDS OF INTACT GCN4. 1DGC 37 REMARK 6 1DGC 38 REMARK 6 BZIP SEQUENCE 220 - 281 USED FOR CRYSTALLIZATION. 1DGC 39 REMARK 7 1DGC 40 REMARK 7 MODEL FROM AMINO ACIDS 227 - 281 SINCE AMINO ACIDS 220 - 1DGC 41 REMARK 7 226 ARE NOT WELL ORDERED. 1DGC 42 REMARK 8 1DGC 43 REMARK 8 RESIDUE NUMBERING OF NUCLEOTIDES: 1DGC 44 REMARK 8 5' T G G A G A T G A C G T C A T C T C C 1DGC 45 REMARK 8 -10 -9 -8 -7 -6 -5 -4 -3 -2 -1 1 2 3 4 5 6 7 8 9 1DGC 46 REMARK 9 1DGC 47 REMARK 9 THE ASYMMETRIC UNIT CONTAINS ONE HALF OF PROTEIN/DNA 1DGC 48 REMARK 9 COMPLEX PER ASYMMETRIC UNIT. 1DGC 49 REMARK 10 1DGC 50 REMARK 10 MOLECULAR DYAD AXIS OF PROTEIN DIMER AND PALINDROMIC HALF 1DGC 51 REMARK 10 SITES OF THE DNA COINCIDES WITH CRYSTALLOGRAPHIC TWO-FOLD 1DGC 52 REMARK 10 AXIS. THE FULL PROTEIN/DNA COMPLEX CAN BE OBTAINED BY 1DGC 53 REMARK 10 APPLYING THE FOLLOWING TRANSFORMATION MATRIX AND 1DGC 54 REMARK 10 TRANSLATION VECTOR TO THE COORDINATES X Y Z: 1DGC 55 REMARK 10 1DGC 56 REMARK 10 0 -1 0 X 117.32 X SYMM 1DGC 57 REMARK 10 -1 0 0 Y + 117.32 = Y SYMM 1DGC 58 REMARK 10 0 0 -1 Z 43.33 Z SYMM 1DGC 59 SEQRES 1 A 62 ILE VAL PRO GLU SER SER ASP PRO ALA ALA LEU LYS ARG 1DGC 60 SEQRES 2 A 62 ALA ARG ASN THR GLU ALA ALA ARG ARG SER ARG ALA ARG 1DGC 61 SEQRES 3 A 62 LYS LEU GLN ARG MET LYS GLN LEU GLU ASP LYS VAL GLU 1DGC 62 SEQRES 4 A 62 GLU LEU LEU SER LYS ASN TYR HIS LEU GLU ASN GLU VAL 1DGC 63 SEQRES 5 A 62 ALA ARG LEU LYS LYS LEU VAL GLY GLU ARG 1DGC 64 SEQRES 1 B 19 T G G A G A T G A C G T C 1DGC 65 SEQRES 2 B 19 A T C T C C 1DGC 66 HELIX 1 A ALA A 228 LYS A 276 1 1DGC 67 CRYST1 58.660 58.660 86.660 90.00 90.00 90.00 P 41 21 2 8 1DGC 68 ORIGX1 1.000000 0.000000 0.000000 0.00000 1DGC 69 ORIGX2 0.000000 1.000000 0.000000 0.00000 1DGC 70 ORIGX3 0.000000 0.000000 1.000000 0.00000 1DGC 71 SCALE1 0.017047 0.000000 0.000000 0.00000 1DGC 72 SCALE2 0.000000 0.017047 0.000000 0.00000 1DGC 73 SCALE3 0.000000 0.000000 0.011539 0.00000 1DGC 74 ATOM 1 N PRO A 227 35.313 108.011 15.140 1.00 38.94 1DGC 75 ATOM 2 CA PRO A 227 34.172 107.658 15.972 1.00 39.82 1DGC 76 ATOM 842 C5 C B 9 57.692 100.286 22.744 1.00 29.82 1DGC 916 ATOM 843 C6 C B 9 58.128 100.193 21.465 1.00 30.63 1DGC 917 TER 844 C B 9 1DGC 918 MASTER 46 0 0 1 0 0 0 6 842 2 0 7 1DGC 919 END 1DGC 920 PDBPDB HEADER COMPND SOURCE AUTHOR DATE JRNL REMARK SECRES ATOM COORDINATES
 1DGC 27 REMARK 3 PERCENT COMPLETION DGC 28 REMARK 3 1DGC 29 REMARK 3 NUMBER OF PROTEIN ATOMS 456 1DGC 30 REMARK 3 NUMBER OF NUCLEIC ACID ATOMS 386 1DGC 31 REMARK 4 1DGC 32 REMARK 4 GCN4: TRANSCRIPTIONAL ACTIVATOR OF GENES ENCODING FOR AMINO 1DGC 33 REMARK 4 ACID BIOSYNTHETIC ENZYMES. 1DGC 34 REMARK 5 1DGC 35 REMARK 5 AMINO ACIDS NUMBERING (RESIDUE NUMBER) CORRESPONDS TO THE 1DGC 36 REMARK AMINO ACIDS OF INTACT GCN4. 1DGC 37 REMARK 6 1DGC 38 REMARK 6 BZIP SEQUENCE USED FOR CRYSTALLIZATION. 1DGC 39 REMARK 7 1DGC 40 REMARK 7 MODEL FROM AMINO ACIDS SINCE AMINO ACIDS DGC 41 REMARK ARE NOT WELL ORDERED. 1DGC 42 REMARK 8 1DGC 43 REMARK 8 RESIDUE NUMBERING OF NUCLEOTIDES: 1DGC 44 REMARK 8 5 T G G A G A T G A C G T C A T C T C C 1DGC 45 REMARK DGC 46 REMARK 9 1DGC 47 REMARK 9 THE ASYMMETRIC UNIT CONTAINS ONE HALF OF PROTEIN/DNA 1DGC 48 REMARK 9 COMPLEX PER ASYMMETRIC UNIT. 1DGC 49 REMARK 10 1DGC 50 REMARK 10 MOLECULAR DYAD AXIS OF PROTEIN DIMER AND PALINDROMIC HALF 1DGC 51 REMARK 10 SITES OF THE DNA COINCIDES WITH CRYSTALLOGRAPHIC TWO-FOLD 1DGC 52 REMARK 10 AXIS. THE FULL PROTEIN/DNA COMPLEX CAN BE OBTAINED BY 1DGC 53 REMARK 10 APPLYING THE FOLLOWING TRANSFORMATION MATRIX AND 1DGC 54 REMARK 10 TRANSLATION VECTOR TO THE COORDINATES X Y Z: 1DGC 55 REMARK 10 1DGC 56 REMARK X X SYMM 1DGC 57 REMARK Y = Y SYMM 1DGC 58 REMARK Z Z SYMM 1DGC 59 SEQRES 1 A 62 ILE VAL PRO GLU SER SER ASP PRO ALA ALA LEU LYS ARG 1DGC 60 SEQRES 2 A 62 ALA ARG ASN THR GLU ALA ALA ARG ARG SER ARG ALA ARG 1DGC 61 SEQRES 3 A 62 LYS LEU GLN ARG MET LYS GLN LEU GLU ASP LYS VAL GLU 1DGC 62 SEQRES 4 A 62 GLU LEU LEU SER LYS ASN TYR HIS LEU GLU ASN GLU VAL 1DGC 63 SEQRES 5 A 62 ALA ARG LEU LYS LYS LEU VAL GLY GLU ARG 1DGC 64 SEQRES 1 B 19 T G G A G A T G A C G T C 1DGC 65 SEQRES 2 B 19 A T C T C C 1DGC 66 HELIX 1 A ALA A 228 LYS A DGC 67 CRYST P DGC 68 ORIGX DGC 69 ORIGX DGC 70 ORIGX DGC 71 SCALE DGC 72 SCALE DGC 73 SCALE DGC 74 ATOM 1 N PRO A DGC 75 ATOM 2 CA PRO A DGC 76 ATOM 842 C5 C B DGC 916 ATOM 843 C6 C B DGC 917 TER 844 C B 9 1DGC 918 MASTER DGC 919 END 1DGC 920 PDBPDB HEADER COMPND SOURCE AUTHOR DATE JRNL REMARK SECRES ATOM COORDINATES.")
44
FormatFormat ASN.1 Flat Files –DNA –Protein FASTA –DNA –Protein

45
Abstract Syntax Notation (ASN.1)
")
46
FASTAFASTA >gi|121066|sp|P03069|GCN4_YEAST GENERAL CONTROL PROTEIN GCN4 MSEYQPSLFALNPMGFSPLDGSKSTNENVSASTSTAKPMVGQLIFDKFIKTEEDPI IKQDTPSNLDFDFALPQTATAPDAKTVLPIPELDDAVVESFFSSSTDSTPMFEYEN LEDNSKEWTSLFDNDIPVTTDDVSLADKAIESTEEVSLVPSNLEVSTTSFLPTPVL EDAKLTQTRKVKKPNSVVKKSHHVGKDDESRLDHLGVVAYNRKQRSIPLSPIVPES SDPAALKRARNTEAARRSRARKLQRMKQLEDKVEELLSKNYHLENEVARLKKLVGE R >gi|121066|sp|P03069|GCN4_YEAST GENERAL CONTROL PROTEIN GCN4>

47
Graphical Representation

48
Guiding Principals In GenBank, records are grouped for various reasons: understand this is key to using and fully taking advantage of this database.

49
IdentifiersIdentifiers You need identifiers which are stable through time Need identifiers which will always refer to specific sequences Need these identifiers to track history of sequence updates Also need feature and annotation identifiers

50
LOCUS, Accession, NID and protein_id LOCUS: Unique string of 10 letters and numbers in the database. Not maintained amongst databases, and is therefore a poor sequence identifier. ACCESSION: A unique identifier to that record, citable entity; does not change when record is updated. A good record identifier, ideal for citation in publication. VERSION: : New system where the accession and version play the same function as the accession and gi number. Nucleotide gi: Geninfo identifier (gi), a unique integer which will change every time the sequence changes. PID: Protein Identifier: g, e or d prefix to gi number. Can have one or two on one CDS. Protein gi: Geninfo identifier (gi), a unique integer which will change every time the sequence changes. protein_id: Identifier which has the same structure and function as the nucleotide Accession.version numbers, but slightlt different format.
, a unique integer which will change every time the sequence changes. PID: Protein Identifier: g, e or d prefix to gi number. Can have one or two on one CDS. Protein gi: Geninfo identifier (gi), a unique integer which will change every time the sequence changes. protein_id: Identifier which has the same structure and function as the nucleotide Accession.version numbers, but slightlt different format..")
51
Accession.version LOCUS, Accession, gi and PID LOCUS HSU40282 1789 bp mRNA PRI 21-MAY-1998 DEFINITION Homo sapiens integrin-linked kinase (ILK) mRNA, complete cds. ACCESSION U40282 VERSION U40282.1 GI:3150001 CDS 157..1515 /gene="ILK" /note="protein serine/threonine kinase" /codon_start=1 /product="integrin-linked kinase" /protein_id="AAC16892.1" /db_xref="PID:g3150002" /db_xref="GI:3150002" LOCUS: HSU40282 ACCESSION: U40282 VERSION: U40282.1 GI: 3150001 PID: g3150002 Protein gi: 3150002 protein_id: AAC16892.1 Protein_idprotein giACCESSIONLOCUSPIDgi

52
EST: Expressed Sequence Tag Expressed Sequence Tags are short (300-500 bp) single reads from mRNA (cDNA) which are produced in large numbers. They represent a snapshot of what is expressed in a given tissue, and developmental stage. Also see: http://www.ncbi.nlm.nih.gov/dbEST/ http://www.ncbi.nlm.nih.gov/UniGene/

53
STSSTS Sequenced Tagged Sites, are operationally unique sequence that identifies the combination of primer pairs used in a PCR assay that generate a mapping reagent which maps to a single position within the genome. Also see: http://www.ncbi.nlm.nih.gov/dbSTS/ http://www.ncbi.nlm.nih.gov/genemap/

54
GSS: Genome Survey Sequences Genome Survey Sequences are similar in nature to the ESTs, except that its sequences are genomic in origin, rather than cDNA (mRNA). The GSS division contains: random "single pass read" genome survey sequences. single pass reads from cosmid/BAC/YAC ends (these could be chromosome specific, but need not be) exon trapped genomic sequences Alu PCR sequences Also see: http://www.ncbi.nlm.nih.gov/dbGSS/
 exon trapped genomic sequences Alu PCR sequences Also see:")
55
HTG: High Throughput Genome High Throughput Genome Sequences are unfinished genome sequencing efforts records. Unfinished records have gaps in the nucleotides sequence, low accuracy, and no annotations on the records. Also see: http://www.ncbi.nlm.nih.gov/HTGS/ Ouellette and Boguski (1997) Genome Res. 7:952-955
 Genome Res. 7:")
56
HTGS in GenBank phase 1 HTG Acc = AC000003 gi = 1556454 phase 2 HTG Acc = AC000003 gi = 2182283 phase 3 PRI Acc = AC000003 gi = 2204282 phase 0 HTG Acc = AC000003 gi = 1235673

57
HTGS in GenBank Unfinished Record –Sequencing will be unfinished –Phase 1 or phase 2 –HTG division –KEYWORDS: HTG; HTGS_PHASE1 or 2 Finished record –Sequencing will be finished –Phase 3 –Organismal division it belongs to PRI,INV or PLN –KEYWORDS: HTG

58
HTC in GenBank GenBank division for unfinished high- throughput cDNA sequencing (HTC). HTC sequences may have 5'UTR and 3'UTR at their ends, partial coding regions, and introns. A keyword of "HTC" will be present, in addition to division code "HTC". Those HTC sequences that undergo finishing (eg, re- sequencing) will move to the appropriate taxonomic GenBank division and the "HTC" keyword will be removed.
 will move to the appropriate taxonomic GenBank division and the HTC keyword will be removed..")
59
Top 5 organisms in the HTC division 64106 Mus musculus 62848 Anopheles gambiae 9119 Zea mays 7732 Homo sapiens 2957 Schmidtea mediterranea

60
WGS in GenBank Contigs from ongoing Whole Genome Shotgun sequencing projects The nucleotides from WGS projects go into the BLAST ‘wgs’ database, whereas the proteins go into the BLAST nr database. More info, and how to submit to this division: http://www.ncbi.nlm.nih.gov/Genbank/wgs.html Accession format is 4+2+6

61
CON in GenBank Points to files that make the contig, does not actually contain sequence ‘Invented’ by NCBI to deal with tracking of segmented sets and 350 KB limit in DDBJ/EMBL/GenBank

62
CON in GenBank LOCUS AH007743 7832 bp DNA CON 26-MAY-1999 DEFINITION Gallus gallus ornithine transcarbamylase (OTC) gene, complete cds. ACCESSION AH007743 VERSION AH007743.1 GI:4927367 KEYWORDS. SOURCE chicken. ORGANISM Gallus gallus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Archosauria; Aves; Neognathae; Galliformes; Phasianidae; Phasianinae; Gallus. [....] FEATURES Location/Qualifiers source 1..7832 /organism="Gallus gallus" /db_xref="taxon:9031" /chromosome="1" CONTIG join(AF065630.1:1..1903,gap(),AF065631.1:1..435,gap(), AF065632.1:1..509,gap(),AF065633.1:1..722,gap(),AF065634.1:1..707, gap(),AF065635.1:1..836,gap(),AF065636.1:1..1614,gap(), AF065637.1:1..605,gap(),AF065638.1:1..501) //
,AF :1..435,gap(), AF :1..509,gap(),AF :1..722,gap(),AF :1..707, gap(),AF :1..836,gap(),AF : ,gap(), AF :1..605,gap(),AF :1..501) //.")
63
Accession number “space” GenBank: –1+5 (L12345, U00001) –2+6 (AF000001, AC000003) WGS (Not distributed with GenBank) –4+2+6 (AAAA01000001, AAAD01000001) Protein: –1+5 (SwissProt/UniProt) –3+5 (GenPept) All have “accession.version”
 –2+6 (AF000001, AC000003) WGS (Not distributed with GenBank) –4+2+6 (AAAA , AAAD ) Protein: –1+5 (SwissProt/UniProt) –3+5 (GenPept) All have accession.version")
64
Secondary Accession Numbers When you ‘retire’ accession numbers, these often are put in the secondary accession number space. (e.g GenBank Accession number L05146) With the removal of sequence length limits, GenBank will now allow continuous ranges of secondary accessions. As of GenBank Release 146.0 (February 2005), it is legal to represent continuous ranges of secondary accessions by a start accession, a dash character, and an end accession. (e.g. for the E. coli genome) ACCESSION U00096 AE000111-AE000510
 With the removal of sequence length limits, GenBank will now allow continuous ranges of secondary accessions. As of GenBank Release (February 2005), it is legal to represent continuous ranges of secondary accessions by a start accession, a dash character, and an end accession. (e.g. for the E. coli genome) ACCESSION U00096 AE AE")
65
GenBank trivia Do you know what the GenBank file size (# of nucleotides) limit used to be before last year? Based on what sequence? Why was there such a file size limit?

66
EST: Expressed Sequence Tag Expressed Sequence Tags are shorter (300-1000 bp) single reads from mRNA (cDNA) which are produced in large numbers. They represent a snapshot of what is expressed in a given tissue, and developmental stage. Also see: http://www.ncbi.nlm.nih.gov/dbEST/ http://www.ncbi.nlm.nih.gov/UniGene/

67
EST growth 1.3.2 Organizational changes The total number of sequence data files increased by 41 with this release: - the BCT division is now comprised of 13 files (+1) - the ENV division is now comprised of 3 files (+1) - the EST division is now comprised of 464 files (+28) - the GSS division is now comprised of 164 files (+6) - the HTG division is now comprised of 69 files (+1) - the PAT division is now comprised of 19 files (+1) - the PLN division is now comprised of 17 files (+1) - the ROD division is now comprised of 23 files (+2)
 - the ENV division is now comprised of 3 files (+1) - the EST division is now comprised of 464 files (+28) - the GSS division is now comprised of 164 files (+6) - the HTG division is now comprised of 69 files (+1) - the PAT division is now comprised of 19 files (+1) - the PLN division is now comprised of 17 files (+1) - the ROD division is now comprised of 23 files (+2)")
68
Sequences NOT in GenBank SNPs SAGE tags RefSeq (Genomic, mRNA, or protein) Consensus sequences
 Consensus sequences")
69
Sequences to Public Databases No longer publish sequences in Journal Electronic format, is most useful Allows validations testing of data best way to move Science forward Sequences sent to DDBJ/EMBL/GenBank are exchanged daily Best way to exchange new data, and updates

70
In closing... Often only use FASTA files (eg for BLAST) GBFF are simply human readable versions of these records GBFF have become a vehicle for a lot more information than they where meant to do Keep in mind that GenBank is DNA centric and is a poor vehicle for protein and mRNA expression/interaction information
 GBFF are simply human readable versions of these records GBFF have become a vehicle for a lot more information than they where meant to do Keep in mind that GenBank is DNA centric and is a poor vehicle for protein and mRNA expression/interaction information.")
71
In closing (cont’d)... Able to recognize various data formats, and know what their primary use is. Know, understand and utilize all types of sequence identifiers. Know and understand various feature types present in the GenBank flat files. Know and understand the various GenBank divisions.

72
In closing (cont’d)... Open access to sequences is not only essential for all of the work we do, if it was not there, there would be no bioinformatics, no BLAST, no CBW As critical as open access to sequence information is the open access to the literature.

73
Closing (part4) I urge you all to only publish in open access journals I urge you to convince your colleagues and mentors to do the same PLoS Biology, BMC genetics, Genome Biology and so forth – great journals! More journals are going open access: be part of what caused this wave!

74
LOCUS CX016035 296 bp mRNA linear EST 06-DEC-2004 DEFINITION qt06h09.g1 Whole Heart Library (DOGEST5) Canis familiaris cDNA, mRNA sequence. ACCESSION CX016035 VERSION CX016035.1 GI:56398446 KEYWORDS EST. SOURCE Canis familiaris (dog) ORGANISM Canis familiaris Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Carnivora; Fissipedia; Canidae; Canis. REFERENCE 1 (bases 1 to 296) AUTHORS Balija,V.S., Nascimento,L.U. and McCombie,W.R. TITLE ESTs from Canis familiaris whole heart (dog) JOURNAL Unpublished (2004) COMMENT Contact: W. Richard McCombie Lita Annenberg Hazen Genome Sequencing Center Cold Spring Harbor Laboratory PO Box 100, Cold Spring Harbor, NY 11724, USA Tel: 516 367 8884 Fax: 516 367 8874 Email: mccombie@cshl.org. LOCUS CX016035 296 bp mRNA linear EST 06-DEC-2004 DEFINITION qt06h09.g1 Whole Heart Library (DOGEST5) Canis familiaris cDNA, mRNA sequence. ACCESSION CX016035 VERSION CX016035.1 GI:56398446 KEYWORDS EST. SOURCE Canis familiaris (dog) ORGANISM Canis familiaris Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Carnivora; Fissipedia; Canidae; Canis. REFERENCE 1 (bases 1 to 296) AUTHORS Balija,V.S., Nascimento,L.U. and McCombie,W.R. TITLE ESTs from Canis familiaris whole heart (dog) JOURNAL Unpublished (2004) COMMENT Contact: W. Richard McCombie Lita Annenberg Hazen Genome Sequencing Center Cold Spring Harbor Laboratory PO Box 100, Cold Spring Harbor, NY 11724, USA Tel: 516 367 8884 Fax: 516 367 8874 Email: mccombie@cshl.org.
 ORGANISM Canis familiaris Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Carnivora; Fissipedia; Canidae; Canis. REFERENCE 1 (bases 1 to 296) AUTHORS Balija,V.S., Nascimento,L.U. and McCombie,W.R. TITLE ESTs from Canis familiaris whole heart (dog) JOURNAL Unpublished (2004) COMMENT Contact: W. Richard McCombie Lita Annenberg Hazen Genome Sequencing Center Cold Spring Harbor Laboratory PO Box 100, Cold Spring Harbor, NY 11724, USA Tel: Fax: LOCUS CX bp mRNA linear EST 06-DEC-2004 DEFINITION qt06h09.g1 Whole Heart Library (DOGEST5) Canis familiaris cDNA, mRNA sequence. ACCESSION CX VERSION CX GI: KEYWORDS EST. SOURCE Canis familiaris (dog) ORGANISM Canis familiaris Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Carnivora; Fissipedia; Canidae; Canis. REFERENCE 1 (bases 1 to 296) AUTHORS Balija,V.S., Nascimento,L.U. and McCombie,W.R. TITLE ESTs from Canis familiaris whole heart (dog) JOURNAL Unpublished (2004) COMMENT Contact: W. Richard McCombie Lita Annenberg Hazen Genome Sequencing Center Cold Spring Harbor Laboratory PO Box 100, Cold Spring Harbor, NY 11724, USA Tel: Fax:")
75
FEATURES Location/Qualifiers source 1..296 /organism="Canis familiaris" /mol_type="mRNA" /db_xref="taxon:9615" /sex="Unknown" /dev_stage="3 month old normal canine" /lab_host="XL10 Gold" /clone_lib="Whole Heart Library (DOGEST5)" /note="Organ: Heart; Vector: pBluescript II SK; Site_1: EcoRI; Site_2: XhoI; Library constructed using pBluescript XR kit from Stratagene. Cloned cDNA was size selected between 1-3 kb. Mark Haskins VMD, PhD, Pathology and Medical Genetics, School of Veterinary Medicine, University of Pennsylvania, 3800 Spruce Street, Philadelphia, PA 19104-6051" ORIGIN 1 ctccaccgcg gtggcggccg ctctagaact agtggatccc ccgggctgca ggaattcggc 61 acgaggaggg tcttttatta aaaccaggtg agtcactcca ttcgctgaga aaaggcacac 121 ttatgttcca gatccacgtc gcctccctcg ggctgggggg tggctggccc actctgtcca 181 gacctctttt tcattacaga tggacactgg ggggcagtga tggatcagag cgttcttatg 241 gccgggcctt ggtttatggc ttggatttgg gatcagaggg gagggtgaag gtgtgg // FEATURES Location/Qualifiers source 1..296 /organism="Canis familiaris" /mol_type="mRNA" /db_xref="taxon:9615" /sex="Unknown" /dev_stage="3 month old normal canine" /lab_host="XL10 Gold" /clone_lib="Whole Heart Library (DOGEST5)" /note="Organ: Heart; Vector: pBluescript II SK; Site_1: EcoRI; Site_2: XhoI; Library constructed using pBluescript XR kit from Stratagene. Cloned cDNA was size selected between 1-3 kb. Mark Haskins VMD, PhD, Pathology and Medical Genetics, School of Veterinary Medicine, University of Pennsylvania, 3800 Spruce Street, Philadelphia, PA 19104-6051" ORIGIN 1 ctccaccgcg gtggcggccg ctctagaact agtggatccc ccgggctgca ggaattcggc 61 acgaggaggg tcttttatta aaaccaggtg agtcactcca ttcgctgaga aaaggcacac 121 ttatgttcca gatccacgtc gcctccctcg ggctgggggg tggctggccc actctgtcca 181 gacctctttt tcattacaga tggacactgg ggggcagtga tggatcagag cgttcttatg 241 gccgggcctt ggtttatggc ttggatttgg gatcagaggg gagggtgaag gtgtgg //
 /note= Organ: Heart; Vector: pBluescript II SK; Site_1: EcoRI; Site_2: XhoI; Library constructed using pBluescript XR kit from Stratagene. Cloned cDNA was size selected between 1-3 kb. Mark Haskins VMD, PhD, Pathology and Medical Genetics, School of Veterinary Medicine, University of Pennsylvania, 3800 Spruce Street, Philadelphia, PA ORIGIN 1 ctccaccgcg gtggcggccg ctctagaact agtggatccc ccgggctgca ggaattcggc 61 acgaggaggg tcttttatta aaaccaggtg agtcactcca ttcgctgaga aaaggcacac 121 ttatgttcca gatccacgtc gcctccctcg ggctgggggg tggctggccc actctgtcca 181 gacctctttt tcattacaga tggacactgg ggggcagtga tggatcagag cgttcttatg 241 gccgggcctt ggtttatggc ttggatttgg gatcagaggg gagggtgaag gtgtgg //.")
76
STSSTS Sequenced Tagged Sites, are operationally unique sequence that identifies the combination of primer pairs used in a PCR assay that generate a mapping reagent which maps to a single position within the genome. Also see: http://www.ncbi.nlm.nih.gov/dbSTS/ http://www.ncbi.nlm.nih.gov/genemap/

77
LOCUS BV102466 500 bp DNA linear STS 29-JAN-2005 DEFINITION 47926ij From 19q13.4 public sequences in the databases from UCSC NT_011109 Homo sapiens STS genomic clone CTC-258N23, sequence tagged site. ACCESSION BV102466 VERSION BV102466.1 GI:58330885 KEYWORDS STS. SOURCE Homo sapiens (human) ORGANISM Homo sapiens Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Homo. REFERENCE 1 (bases 1 to 500) AUTHORS Slim,R., Fallahian,M., Riviere,J.-B. and Zali,M.R. TITLE Evidence of genetic heterogeneity of familial hydatidiform moles JOURNAL Placenta 26 (1), 5-9 (2005) MEDLINE 15664405 LOCUS BV102466 500 bp DNA linear STS 29-JAN-2005 DEFINITION 47926ij From 19q13.4 public sequences in the databases from UCSC NT_011109 Homo sapiens STS genomic clone CTC-258N23, sequence tagged site. ACCESSION BV102466 VERSION BV102466.1 GI:58330885 KEYWORDS STS. SOURCE Homo sapiens (human) ORGANISM Homo sapiens Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Homo. REFERENCE 1 (bases 1 to 500) AUTHORS Slim,R., Fallahian,M., Riviere,J.-B. and Zali,M.R. TITLE Evidence of genetic heterogeneity of familial hydatidiform moles JOURNAL Placenta 26 (1), 5-9 (2005) MEDLINE 15664405
 ORGANISM Homo sapiens Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Homo. REFERENCE 1 (bases 1 to 500) AUTHORS Slim,R., Fallahian,M., Riviere,J.-B. and Zali,M.R. TITLE Evidence of genetic heterogeneity of familial hydatidiform moles JOURNAL Placenta 26 (1), 5-9 (2005) MEDLINE LOCUS BV bp DNA linear STS 29-JAN-2005 DEFINITION 47926ij From 19q13.4 public sequences in the databases from UCSC NT_ Homo sapiens STS genomic clone CTC-258N23, sequence tagged site. ACCESSION BV VERSION BV GI: KEYWORDS STS. SOURCE Homo sapiens (human) ORGANISM Homo sapiens Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Homo. REFERENCE 1 (bases 1 to 500) AUTHORS Slim,R., Fallahian,M., Riviere,J.-B. and Zali,M.R. TITLE Evidence of genetic heterogeneity of familial hydatidiform moles JOURNAL Placenta 26 (1), 5-9 (2005) MEDLINE")
78
COMMENT Contact: Rima Slim McGill University Health Center, Montreal General Hospital Research Institute room L12-132, 1650 Cedar Avenue, H3G 1A4, Montreal, Canada Tel: (514) 934-1934 ext 44519 Fax: (514) 934 8265 Email: rima.slim@muhc.mcgill.ca Primer A: CCGAGTGGGGTGGCACAT Primer B: GGTGGAGCAATTGGGAAGATACTA STS size: 260 PCR Profile: Presoak: 0 degrees C for 0.00 minute (s) Denaturation: 94 degrees C for 4.00 minute (s) Denaturation: 94 degrees C for 0.45 minute (s) Annealing: 55 degrees C for 0.45 minute (s) Polymerization: 72 degrees C for 1.00 minute (s) PCR cycles: 35 Thermal Cycler: Perkin Elmer Gene Amp 9700 Protocol: Template: 200ng Primer: each 1uM dNTPs: each 200 uM Taq Polymerase: 0.07 unit/ul Total volume: 13ul Buffer: MgCl2: 1.5 mM KCl: 50mM Tris-HCl: 10mM PH: 8.3. COMMENT Contact: Rima Slim McGill University Health Center, Montreal General Hospital Research Institute room L12-132, 1650 Cedar Avenue, H3G 1A4, Montreal, Canada Tel: (514) 934-1934 ext 44519 Fax: (514) 934 8265 Email: rima.slim@muhc.mcgill.ca Primer A: CCGAGTGGGGTGGCACAT Primer B: GGTGGAGCAATTGGGAAGATACTA STS size: 260 PCR Profile: Presoak: 0 degrees C for 0.00 minute (s) Denaturation: 94 degrees C for 4.00 minute (s) Denaturation: 94 degrees C for 0.45 minute (s) Annealing: 55 degrees C for 0.45 minute (s) Polymerization: 72 degrees C for 1.00 minute (s) PCR cycles: 35 Thermal Cycler: Perkin Elmer Gene Amp 9700 Protocol: Template: 200ng Primer: each 1uM dNTPs: each 200 uM Taq Polymerase: 0.07 unit/ul Total volume: 13ul Buffer: MgCl2: 1.5 mM KCl: 50mM Tris-HCl: 10mM PH: 8.3.
 ext Fax: (514) Primer A: CCGAGTGGGGTGGCACAT Primer B: GGTGGAGCAATTGGGAAGATACTA STS size: 260 PCR Profile: Presoak: 0 degrees C for 0.00 minute (s) Denaturation: 94 degrees C for 4.00 minute (s) Denaturation: 94 degrees C for 0.45 minute (s) Annealing: 55 degrees C for 0.45 minute (s) Polymerization: 72 degrees C for 1.00 minute (s) PCR cycles: 35 Thermal Cycler: Perkin Elmer Gene Amp 9700 Protocol: Template: 200ng Primer: each 1uM dNTPs: each 200 uM Taq Polymerase: 0.07 unit/ul Total volume: 13ul Buffer: MgCl2: 1.5 mM KCl: 50mM Tris-HCl: 10mM PH:")
79
FEATURES Location/Qualifiers source 1..500 /organism="Homo sapiens" /mol_type="genomic DNA" /db_xref="taxon:9606" /map="19q13.4" /clone="CTC-258N23" /clone_lib="From 19q13.4 public sequences in the databases from UCSC NT_011109" /note="From public sequences in the databases from UCSC NT_011109" STS 64..323 primer_bind 64..81 primer_bind complement(300..323) ORIGIN 1 ataccagcct agactacaaa gtgagatccc atttctacaa aaataaaaat tagctgggct 61 cagccgagtg gggtggcaca tgcctgtagt cccagctact caggaggctg aggcgggagg 121 ctcgcttgag cctaggagtt gggggctgca atgagctatg attttgccac tgcactccag 181 cctgggcaac agagtgaggc cctgtctcaa aaatacacac acacacgcac acacacacac 241 acacacactt aaaaaacaaa aggttgaaaa tgaaacacat agtgaaataa aagttctgat 301 agtatcttcc caattgctcc acctcacttt agagtcaggt gagggaggat ggtggcggag 361 gctgcaacac agtggctgag acatcgctct cagcgtgtca ccgtgaggtc tcccagggag 421 ggtgtggaga aaacagtgcc caggacagag cctgagaaac ctcaccggga agatggagca 481 taacaaggaa agcattactc // FEATURES Location/Qualifiers source 1..500 /organism="Homo sapiens" /mol_type="genomic DNA" /db_xref="taxon:9606" /map="19q13.4" /clone="CTC-258N23" /clone_lib="From 19q13.4 public sequences in the databases from UCSC NT_011109" /note="From public sequences in the databases from UCSC NT_011109" STS 64..323 primer_bind 64..81 primer_bind complement(300..323) ORIGIN 1 ataccagcct agactacaaa gtgagatccc atttctacaa aaataaaaat tagctgggct 61 cagccgagtg gggtggcaca tgcctgtagt cccagctact caggaggctg aggcgggagg 121 ctcgcttgag cctaggagtt gggggctgca atgagctatg attttgccac tgcactccag 181 cctgggcaac agagtgaggc cctgtctcaa aaatacacac acacacgcac acacacacac 241 acacacactt aaaaaacaaa aggttgaaaa tgaaacacat agtgaaataa aagttctgat 301 agtatcttcc caattgctcc acctcacttt agagtcaggt gagggaggat ggtggcggag 361 gctgcaacac agtggctgag acatcgctct cagcgtgtca ccgtgaggtc tcccagggag 421 ggtgtggaga aaacagtgcc caggacagag cctgagaaac ctcaccggga agatggagca 481 taacaaggaa agcattactc //
 ORIGIN 1 ataccagcct agactacaaa gtgagatccc atttctacaa aaataaaaat tagctgggct 61 cagccgagtg gggtggcaca tgcctgtagt cccagctact caggaggctg aggcgggagg 121 ctcgcttgag cctaggagtt gggggctgca atgagctatg attttgccac tgcactccag 181 cctgggcaac agagtgaggc cctgtctcaa aaatacacac acacacgcac acacacacac 241 acacacactt aaaaaacaaa aggttgaaaa tgaaacacat agtgaaataa aagttctgat 301 agtatcttcc caattgctcc acctcacttt agagtcaggt gagggaggat ggtggcggag 361 gctgcaacac agtggctgag acatcgctct cagcgtgtca ccgtgaggtc tcccagggag 421 ggtgtggaga aaacagtgcc caggacagag cctgagaaac ctcaccggga agatggagca 481 taacaaggaa agcattactc // FEATURES Location/Qualifiers source /organism= Homo sapiens /mol_type= genomic DNA /db_xref= taxon:9606 /map= 19q13.4 /clone= CTC-258N23 /clone_lib= From 19q13.4 public sequences in the databases from UCSC NT_ /note= From public sequences in the databases from UCSC NT_ STS primer_bind primer_bind complement( ) ORIGIN 1 ataccagcct agactacaaa gtgagatccc atttctacaa aaataaaaat tagctgggct 61 cagccgagtg gggtggcaca tgcctgtagt cccagctact caggaggctg aggcgggagg 121 ctcgcttgag cctaggagtt gggggctgca atgagctatg attttgccac tgcactccag 181 cctgggcaac agagtgaggc cctgtctcaa aaatacacac acacacgcac acacacacac 241 acacacactt aaaaaacaaa aggttgaaaa tgaaacacat agtgaaataa aagttctgat 301 agtatcttcc caattgctcc acctcacttt agagtcaggt gagggaggat ggtggcggag 361 gctgcaacac agtggctgag acatcgctct cagcgtgtca ccgtgaggtc tcccagggag 421 ggtgtggaga aaacagtgcc caggacagag cctgagaaac ctcaccggga agatggagca 481 taacaaggaa agcattactc //")
80
GSS: Genome Survey Sequences Genome Survey Sequences are similar in nature to the ESTs, except that its sequences are genomic in origin, rather than cDNA (mRNA). The GSS division contains: random "single pass read" genome survey sequences. single pass reads from cosmid/BAC/YAC ends (these could be chromosome specific, but need not be) exon trapped genomic sequences Alu PCR sequences Also see: http://www.ncbi.nlm.nih.gov/dbGSS/
 exon trapped genomic sequences Alu PCR sequences Also see:")
81
HTG: High Throughput Genome High Throughput Genome Sequences are unfinished genome sequencing efforts records. Unfinished records have gaps in the nucleotides sequence, low accuracy, and no annotations on the records. Also see: http://www.ncbi.nlm.nih.gov/HTGS/ Ouellette and Boguski (1997) Genome Res. 7:952-955
 Genome Res. 7:")
82
HTGS in GenBank phase 1 HTG Acc = AC000003 gi = 1556454 phase 2 HTG Acc = AC000003 gi = 2182283 phase 3 PRI Acc = AC000003 gi = 2204282 phase 0 HTG Acc = AC000003 gi = 1235673

83
HTGS in GenBank Unfinished Record –Sequencing will be unfinished –Phase 1 or phase 2 –HTG division –KEYWORDS: HTG; HTGS_PHASE1 or 2 Finished record –Sequencing will be finished –Phase 3 –Organismal division it belongs to PRI,INV or PLN –KEYWORDS: HTG

84
HTC in GenBank GenBank division for unfinished high- throughput cDNA sequencing (HTC). HTC sequences may have 5'UTR and 3'UTR at their ends, partial coding regions, and introns. A keyword of "HTC" will be present, in addition to division code "HTC". Those HTC sequences that undergo finishing (eg, re- sequencing) will move to the appropriate taxonomic GenBank division and the "HTC" keyword will be removed.
 will move to the appropriate taxonomic GenBank division and the HTC keyword will be removed..")
85
LOCUS CR926482 2728 bp RNA linear HTC 11-JAN-2005 DEFINITION Pongo pygmaeus mRNA; cDNA DKFZp469F2123 (from clone DKFZp469F2123). ACCESSION CR926482 VERSION CR926482.1 GI:56541783 KEYWORDS HTC. SOURCE Pongo pygmaeus (orangutan) ORGANISM Pongo pygmaeus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Pongo. REFERENCE 1 (bases 1 to 2728) AUTHORS Ansorge,W., Krieger,S., Regiert,T., Rittmueller,C., Schwager,B., Mewes,H.W., Weil,B., Amid,C., Osanger,A., Fobo,G., Han,M. and Wiemann,S. CONSRTM The German cDNA Consortium TITLE Direct Submission JOURNAL Submitted (08-DEC-2004) MIPS, Ingolstaedter Landstr.1, D-85764 Neuherberg, GERMANY COMMENT Clone from S. Wiemann, Molecular Genome Analysis, German Cancer Research Center (DKFZ); Email s.wiemann@dkfz-heidelberg.de; sequenced by EMBL (European Molecular Biology Laboratories, Heidelberg/Germany) within the cDNA sequencing consortium of the German Genome Project. This clone (DKFZp469F2123) is available at the RZPD Deutsches Ressourcenzentrum fuer Genomforschung GmbH in Berlin, Germany. Please contact RZPD for ordering: http://www.rzpd.de/cgi-bin/products/cl.cgi?CloneID=DKFZp469F2123 Further information about the clone and the sequencing project is available at http://mips.gsf.de/projects/cdna/. LOCUS CR926482 2728 bp RNA linear HTC 11-JAN-2005 DEFINITION Pongo pygmaeus mRNA; cDNA DKFZp469F2123 (from clone DKFZp469F2123). ACCESSION CR926482 VERSION CR926482.1 GI:56541783 KEYWORDS HTC. SOURCE Pongo pygmaeus (orangutan) ORGANISM Pongo pygmaeus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Pongo. REFERENCE 1 (bases 1 to 2728) AUTHORS Ansorge,W., Krieger,S., Regiert,T., Rittmueller,C., Schwager,B., Mewes,H.W., Weil,B., Amid,C., Osanger,A., Fobo,G., Han,M. and Wiemann,S. CONSRTM The German cDNA Consortium TITLE Direct Submission JOURNAL Submitted (08-DEC-2004) MIPS, Ingolstaedter Landstr.1, D-85764 Neuherberg, GERMANY COMMENT Clone from S. Wiemann, Molecular Genome Analysis, German Cancer Research Center (DKFZ); Email s.wiemann@dkfz-heidelberg.de; sequenced by EMBL (European Molecular Biology Laboratories, Heidelberg/Germany) within the cDNA sequencing consortium of the German Genome Project. This clone (DKFZp469F2123) is available at the RZPD Deutsches Ressourcenzentrum fuer Genomforschung GmbH in Berlin, Germany. Please contact RZPD for ordering: http://www.rzpd.de/cgi-bin/products/cl.cgi?CloneID=DKFZp469F2123 Further information about the clone and the sequencing project is available at http://mips.gsf.de/projects/cdna/.
 ORGANISM Pongo pygmaeus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Pongo. REFERENCE 1 (bases 1 to 2728) AUTHORS Ansorge,W., Krieger,S., Regiert,T., Rittmueller,C., Schwager,B., Mewes,H.W., Weil,B., Amid,C., Osanger,A., Fobo,G., Han,M. and Wiemann,S. CONSRTM The German cDNA Consortium TITLE Direct Submission JOURNAL Submitted (08-DEC-2004) MIPS, Ingolstaedter Landstr.1, D Neuherberg, GERMANY COMMENT Clone from S. Wiemann, Molecular Genome Analysis, German Cancer Research Center (DKFZ); sequenced by EMBL (European Molecular Biology Laboratories, Heidelberg/Germany) within the cDNA sequencing consortium of the German Genome Project. This clone (DKFZp469F2123) is available at the RZPD Deutsches Ressourcenzentrum fuer Genomforschung GmbH in Berlin, Germany. Please contact RZPD for ordering: CloneID=DKFZp469F2123 Further information about the clone and the sequencing project is available at LOCUS CR bp RNA linear HTC 11-JAN-2005 DEFINITION Pongo pygmaeus mRNA; cDNA DKFZp469F2123 (from clone DKFZp469F2123). ACCESSION CR VERSION CR GI: KEYWORDS HTC. SOURCE Pongo pygmaeus (orangutan) ORGANISM Pongo pygmaeus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Pongo. REFERENCE 1 (bases 1 to 2728) AUTHORS Ansorge,W., Krieger,S., Regiert,T., Rittmueller,C., Schwager,B., Mewes,H.W., Weil,B., Amid,C., Osanger,A., Fobo,G., Han,M. and Wiemann,S. CONSRTM The German cDNA Consortium TITLE Direct Submission JOURNAL Submitted (08-DEC-2004) MIPS, Ingolstaedter Landstr.1, D Neuherberg, GERMANY COMMENT Clone from S. Wiemann, Molecular Genome Analysis, German Cancer Research Center (DKFZ); sequenced by EMBL (European Molecular Biology Laboratories, Heidelberg/Germany) within the cDNA sequencing consortium of the German Genome Project. This clone (DKFZp469F2123) is available at the RZPD Deutsches Ressourcenzentrum fuer Genomforschung GmbH in Berlin, Germany. Please contact RZPD for ordering: CloneID=DKFZp469F2123 Further information about the clone and the sequencing project is available at")
86
FEATURES Location/Qualifiers source 1..2728 /organism="Pongo pygmaeus" /mol_type="pre-RNA" /db_xref="taxon:9600" /clone="DKFZp469F2123" /tissue_type="kidney" /clone_lib="469 (synonym: pkid1). Vector pSport1_Sfi; host DH10B; sites SfilA + SfilB" /dev_stage="adult" /note="Rh type C glycoprotein (Homo sapiens), not fully spliced" gene join(40..165,194..1015,1217..1354,1663..1788,2038..2244) /gene="DKFZp469F2123" CDS join(40..165,194..1015,1217..1354,1663..1788,2038..2244) /gene="DKFZp469F2123" /codon_start=1 /product="hypothetical protein" /protein_id="CAI30274.1" /db_xref="GI:56541784" /translation="MAWNTNLRWRLPLTCLLLEVVMVILFGVFVRYDFDADAHWWSWR TEFYYRYPSFQDVHVMVFVGFGFLMTFLQRYGFSAVGFNFLLAAFGIQWALLMQGWFH FLQGRYIVVGVENLINADFCVASVCVAFGAVLGKVSPIQLLIMTFFQVTLFAVNEFIL LNLLKVKDAGGSMTIHTFGAYFGLTVTRILYRRNLEQSKERQNSVYQSDLFAMIGTLF LWMYWPSFNSAISYHGDSQHRAAINTYCSLAACVLTSVAISSALHKKGKLDMVHIQNA TPAGGVAVGTAAEMMLMPYGALIVGFVCGIISTLGFVYLTPFLESRLHIQDTCGINNL HGIPGIIGGIVGAVTAASASLEVYGKEGLVHSFDFQGFKRDWTARTQGKFQIYGLLVT LAMALMGGIIVGVGLILRLPFWGQPSDENCFEDAVYWEMPEGNSTVYIPEDPTFKPSG PSVPSVPMVSPLPMASSVPLVP" ORIGIN 1 gaaccgcccg ctgcccgccc ggcccggcac ccctgcagca tggcctggaa caccaacctc 61 cgctggcggc tgccgctcac ctgcctgctc ctggaggtgg ttatggtgat tctctttggg 121 gtgttcgtgc gctacgactt cgacgccgac gcccactggt ggtcacagac gaagcacaag 181 aacttgagcg acgtggagaa ccgaattcta ctatcgctac ccaagcttcc aggacgtgca 241 cgtgatggtc ttcgtgggct tcggcttcct catgaccttc ctgcagcgct acggcttcag 301 cgccgtgggc ttcaacttcc tgttggcggc cttcggcatc cagtgggcgc tgctcatgca 361 gggctggttc cacttcttac aaggccgcta catcgtcgtg ggcgtggaga acctcatcaa 421 cgctgacttc tgcgtggcct ctgtctgcgt ggcttttggg gcagttctgg gtaaagtcag 481 ccccattcag ctactcatca tgactttctt ccaagtgacc ctcttcgccg tgaatgagtt FEATURES Location/Qualifiers source 1..2728 /organism="Pongo pygmaeus" /mol_type="pre-RNA" /db_xref="taxon:9600" /clone="DKFZp469F2123" /tissue_type="kidney" /clone_lib="469 (synonym: pkid1). Vector pSport1_Sfi; host DH10B; sites SfilA + SfilB" /dev_stage="adult" /note="Rh type C glycoprotein (Homo sapiens), not fully spliced" gene join(40..165,194..1015,1217..1354,1663..1788,2038..2244) /gene="DKFZp469F2123" CDS join(40..165,194..1015,1217..1354,1663..1788,2038..2244) /gene="DKFZp469F2123" /codon_start=1 /product="hypothetical protein" /protein_id="CAI30274.1" /db_xref="GI:56541784" /translation="MAWNTNLRWRLPLTCLLLEVVMVILFGVFVRYDFDADAHWWSWR TEFYYRYPSFQDVHVMVFVGFGFLMTFLQRYGFSAVGFNFLLAAFGIQWALLMQGWFH FLQGRYIVVGVENLINADFCVASVCVAFGAVLGKVSPIQLLIMTFFQVTLFAVNEFIL LNLLKVKDAGGSMTIHTFGAYFGLTVTRILYRRNLEQSKERQNSVYQSDLFAMIGTLF LWMYWPSFNSAISYHGDSQHRAAINTYCSLAACVLTSVAISSALHKKGKLDMVHIQNA TPAGGVAVGTAAEMMLMPYGALIVGFVCGIISTLGFVYLTPFLESRLHIQDTCGINNL HGIPGIIGGIVGAVTAASASLEVYGKEGLVHSFDFQGFKRDWTARTQGKFQIYGLLVT LAMALMGGIIVGVGLILRLPFWGQPSDENCFEDAVYWEMPEGNSTVYIPEDPTFKPSG PSVPSVPMVSPLPMASSVPLVP" ORIGIN 1 gaaccgcccg ctgcccgccc ggcccggcac ccctgcagca tggcctggaa caccaacctc 61 cgctggcggc tgccgctcac ctgcctgctc ctggaggtgg ttatggtgat tctctttggg 121 gtgttcgtgc gctacgactt cgacgccgac gcccactggt ggtcacagac gaagcacaag 181 aacttgagcg acgtggagaa ccgaattcta ctatcgctac ccaagcttcc aggacgtgca 241 cgtgatggtc ttcgtgggct tcggcttcct catgaccttc ctgcagcgct acggcttcag 301 cgccgtgggc ttcaacttcc tgttggcggc cttcggcatc cagtgggcgc tgctcatgca 361 gggctggttc cacttcttac aaggccgcta catcgtcgtg ggcgtggaga acctcatcaa 421 cgctgacttc tgcgtggcct ctgtctgcgt ggcttttggg gcagttctgg gtaaagtcag 481 ccccattcag ctactcatca tgactttctt ccaagtgacc ctcttcgccg tgaatgagtt
, not fully spliced gene join( , , , , ) /gene= DKFZp469F2123 CDS join( , , , , ) /gene= DKFZp469F2123 /codon_start=1 /product= hypothetical protein /protein_id= CAI /db_xref= GI: /translation= MAWNTNLRWRLPLTCLLLEVVMVILFGVFVRYDFDADAHWWSWR TEFYYRYPSFQDVHVMVFVGFGFLMTFLQRYGFSAVGFNFLLAAFGIQWALLMQGWFH FLQGRYIVVGVENLINADFCVASVCVAFGAVLGKVSPIQLLIMTFFQVTLFAVNEFIL LNLLKVKDAGGSMTIHTFGAYFGLTVTRILYRRNLEQSKERQNSVYQSDLFAMIGTLF LWMYWPSFNSAISYHGDSQHRAAINTYCSLAACVLTSVAISSALHKKGKLDMVHIQNA TPAGGVAVGTAAEMMLMPYGALIVGFVCGIISTLGFVYLTPFLESRLHIQDTCGINNL HGIPGIIGGIVGAVTAASASLEVYGKEGLVHSFDFQGFKRDWTARTQGKFQIYGLLVT LAMALMGGIIVGVGLILRLPFWGQPSDENCFEDAVYWEMPEGNSTVYIPEDPTFKPSG PSVPSVPMVSPLPMASSVPLVP ORIGIN 1 gaaccgcccg ctgcccgccc ggcccggcac ccctgcagca tggcctggaa caccaacctc 61 cgctggcggc tgccgctcac ctgcctgctc ctggaggtgg ttatggtgat tctctttggg 121 gtgttcgtgc gctacgactt cgacgccgac gcccactggt ggtcacagac gaagcacaag 181 aacttgagcg acgtggagaa ccgaattcta ctatcgctac ccaagcttcc aggacgtgca 241 cgtgatggtc ttcgtgggct tcggcttcct catgaccttc ctgcagcgct acggcttcag 301 cgccgtgggc ttcaacttcc tgttggcggc cttcggcatc cagtgggcgc tgctcatgca 361 gggctggttc cacttcttac aaggccgcta catcgtcgtg ggcgtggaga acctcatcaa 421 cgctgacttc tgcgtggcct ctgtctgcgt ggcttttggg gcagttctgg gtaaagtcag 481 ccccattcag ctactcatca tgactttctt ccaagtgacc ctcttcgccg tgaatgagtt FEATURES Location/Qualifiers source /organism= Pongo pygmaeus /mol_type= pre-RNA /db_xref= taxon:9600 /clone= DKFZp469F2123 /tissue_type= kidney /clone_lib= 469 (synonym: pkid1). Vector pSport1_Sfi; host DH10B; sites SfilA + SfilB /dev_stage= adult /note= Rh type C glycoprotein (Homo sapiens), not fully spliced gene join( , , , , ) /gene= DKFZp469F2123 CDS join( , , , , ) /gene= DKFZp469F2123 /codon_start=1 /product= hypothetical protein /protein_id= CAI /db_xref= GI: /translation= MAWNTNLRWRLPLTCLLLEVVMVILFGVFVRYDFDADAHWWSWR TEFYYRYPSFQDVHVMVFVGFGFLMTFLQRYGFSAVGFNFLLAAFGIQWALLMQGWFH FLQGRYIVVGVENLINADFCVASVCVAFGAVLGKVSPIQLLIMTFFQVTLFAVNEFIL LNLLKVKDAGGSMTIHTFGAYFGLTVTRILYRRNLEQSKERQNSVYQSDLFAMIGTLF LWMYWPSFNSAISYHGDSQHRAAINTYCSLAACVLTSVAISSALHKKGKLDMVHIQNA TPAGGVAVGTAAEMMLMPYGALIVGFVCGIISTLGFVYLTPFLESRLHIQDTCGINNL HGIPGIIGGIVGAVTAASASLEVYGKEGLVHSFDFQGFKRDWTARTQGKFQIYGLLVT LAMALMGGIIVGVGLILRLPFWGQPSDENCFEDAVYWEMPEGNSTVYIPEDPTFKPSG PSVPSVPMVSPLPMASSVPLVP ORIGIN 1 gaaccgcccg ctgcccgccc ggcccggcac ccctgcagca tggcctggaa caccaacctc 61 cgctggcggc tgccgctcac ctgcctgctc ctggaggtgg ttatggtgat tctctttggg 121 gtgttcgtgc gctacgactt cgacgccgac gcccactggt ggtcacagac gaagcacaag 181 aacttgagcg acgtggagaa ccgaattcta ctatcgctac ccaagcttcc aggacgtgca 241 cgtgatggtc ttcgtgggct tcggcttcct catgaccttc ctgcagcgct acggcttcag 301 cgccgtgggc ttcaacttcc tgttggcggc cttcggcatc cagtgggcgc tgctcatgca 361 gggctggttc cacttcttac aaggccgcta catcgtcgtg ggcgtggaga acctcatcaa 421 cgctgacttc tgcgtggcct ctgtctgcgt ggcttttggg gcagttctgg gtaaagtcag 481 ccccattcag ctactcatca tgactttctt ccaagtgacc ctcttcgccg tgaatgagtt.")
87
WGS (Not in GenBank release) Contigs from ongoing Whole Genome Shotgun sequencing projects The nucleotides from WGS projects go into the BLAST ‘wgs’ database, whereas the proteins go into the BLAST nr database. More info, and how to submit to this division: http://www.ncbi.nlm.nih.gov/Genbank/wgs.html Accession format is 4+2+6

88
CON in GenBank Points to files that make the contig, does not actually contain sequence ‘Invented’ by NCBI to deal with tracking of segmented sets and 350 KB limit in DDBJ/EMBL/GenBank

89
CON in GenBank LOCUS AH007743 7832 bp DNA CON 26-MAY- 1999 DEFINITION Gallus gallus ornithine transcarbamylase (OTC) gene, complete cds. ACCESSION AH007743 VERSION AH007743.1 GI:4927367 KEYWORDS. SOURCE chicken. ORGANISM Gallus gallus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Archosauria; Aves; Neognathae; Galliformes; Phasianidae; Phasianinae; Gallus. [....] FEATURES Location/Qualifiers source 1..7832 /organism="Gallus gallus" /db_xref="taxon:9031" /chromosome="1" CONTIG join(AF065630.1:1..1903,gap(),AF065631.1:1..435,gap(), AF065632.1:1..509,gap(),AF065633.1:1..722,gap(),AF065634.1:1..707, gap(),AF065635.1:1..836,gap(),AF065636.1:1..1614,gap(), AF065637.1:1..605,gap(),AF065638.1:1..501) // LOCUS AH007743 7832 bp DNA CON 26-MAY- 1999 DEFINITION Gallus gallus ornithine transcarbamylase (OTC) gene, complete cds. ACCESSION AH007743 VERSION AH007743.1 GI:4927367 KEYWORDS. SOURCE chicken. ORGANISM Gallus gallus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Archosauria; Aves; Neognathae; Galliformes; Phasianidae; Phasianinae; Gallus. [....] FEATURES Location/Qualifiers source 1..7832 /organism="Gallus gallus" /db_xref="taxon:9031" /chromosome="1" CONTIG join(AF065630.1:1..1903,gap(),AF065631.1:1..435,gap(), AF065632.1:1..509,gap(),AF065633.1:1..722,gap(),AF065634.1:1..707, gap(),AF065635.1:1..836,gap(),AF065636.1:1..1614,gap(), AF065637.1:1..605,gap(),AF065638.1:1..501) //
,AF :1..435,gap(), AF :1..509,gap(),AF :1..722,gap(),AF :1..707, gap(),AF :1..836,gap(),AF : ,gap(), AF :1..605,gap(),AF :1..501) // LOCUS AH bp DNA CON 26-MAY DEFINITION Gallus gallus ornithine transcarbamylase (OTC) gene, complete cds. ACCESSION AH VERSION AH GI: KEYWORDS. SOURCE chicken. ORGANISM Gallus gallus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Archosauria; Aves; Neognathae; Galliformes; Phasianidae; Phasianinae; Gallus. [....] FEATURES Location/Qualifiers source /organism= Gallus gallus /db_xref= taxon:9031 /chromosome= 1 CONTIG join(AF : ,gap(),AF :1..435,gap(), AF :1..509,gap(),AF :1..722,gap(),AF :1..707, gap(),AF :1..836,gap(),AF : ,gap(), AF :1..605,gap(),AF :1..501) //.")
90
Rat GenBank CON record for Chromosome X LOCUS CM000092 160699376 bp DNA linear CON 13-DEC-2004 DEFINITION Rattus norvegicus strain BN/SsNHsdMCW chromosome X. ACCESSION CM000092 VERSION CM000092.1 GI:56553605 KEYWORDS. SOURCE Rattus norvegicus (Norway rat) ORGANISM Rattus norvegicus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Rodentia; Sciurognathi; Muridae; Murinae; Rattus. REFERENCE 1 (bases 1 to 160699376) AUTHORS. CONSRTM Rat Genome Sequencing Project Consortium TITLE Genome sequence of the Brown Norway rat yields insights into mammalian evolution JOURNAL Nature 428 (6982), 493-521 (2004) PUBMED 15057822 REFERENCE 2 (bases 1 to 160699376) AUTHORS. CONSRTM Rat Genome Sequencing Consortium TITLE Direct Submission JOURNAL Submitted (30-SEP-2004) Human Genome Sequencing Center, Department of Molecular and Human Genetics, Baylor College of Medicine, One Baylor Plaza, Houston, TX 77030, USA REMARK Contact ncbi-contacts@bcm.tmc.edu for more information. FEATURES Location/Qualifiers LOCUS CM000092 160699376 bp DNA linear CON 13-DEC-2004 DEFINITION Rattus norvegicus strain BN/SsNHsdMCW chromosome X. ACCESSION CM000092 VERSION CM000092.1 GI:56553605 KEYWORDS. SOURCE Rattus norvegicus (Norway rat) ORGANISM Rattus norvegicus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Rodentia; Sciurognathi; Muridae; Murinae; Rattus. REFERENCE 1 (bases 1 to 160699376) AUTHORS. CONSRTM Rat Genome Sequencing Project Consortium TITLE Genome sequence of the Brown Norway rat yields insights into mammalian evolution JOURNAL Nature 428 (6982), 493-521 (2004) PUBMED 15057822 REFERENCE 2 (bases 1 to 160699376) AUTHORS. CONSRTM Rat Genome Sequencing Consortium TITLE Direct Submission JOURNAL Submitted (30-SEP-2004) Human Genome Sequencing Center, Department of Molecular and Human Genetics, Baylor College of Medicine, One Baylor Plaza, Houston, TX 77030, USA REMARK Contact ncbi-contacts@bcm.tmc.edu for more information. FEATURES Location/Qualifiers
 ORGANISM Rattus norvegicus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Rodentia; Sciurognathi; Muridae; Murinae; Rattus. REFERENCE 1 (bases 1 to ) AUTHORS. CONSRTM Rat Genome Sequencing Project Consortium TITLE Genome sequence of the Brown Norway rat yields insights into mammalian evolution JOURNAL Nature 428 (6982), (2004) PUBMED REFERENCE 2 (bases 1 to ) AUTHORS. CONSRTM Rat Genome Sequencing Consortium TITLE Direct Submission JOURNAL Submitted (30-SEP-2004) Human Genome Sequencing Center, Department of Molecular and Human Genetics, Baylor College of Medicine, One Baylor Plaza, Houston, TX 77030, USA REMARK Contact for more information. FEATURES Location/Qualifiers LOCUS CM bp DNA linear CON 13-DEC-2004 DEFINITION Rattus norvegicus strain BN/SsNHsdMCW chromosome X. ACCESSION CM VERSION CM GI: KEYWORDS. SOURCE Rattus norvegicus (Norway rat) ORGANISM Rattus norvegicus Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Rodentia; Sciurognathi; Muridae; Murinae; Rattus. REFERENCE 1 (bases 1 to ) AUTHORS. CONSRTM Rat Genome Sequencing Project Consortium TITLE Genome sequence of the Brown Norway rat yields insights into mammalian evolution JOURNAL Nature 428 (6982), (2004) PUBMED REFERENCE 2 (bases 1 to ) AUTHORS. CONSRTM Rat Genome Sequencing Consortium TITLE Direct Submission JOURNAL Submitted (30-SEP-2004) Human Genome Sequencing Center, Department of Molecular and Human Genetics, Baylor College of Medicine, One Baylor Plaza, Houston, TX 77030, USA REMARK Contact for more information. FEATURES Location/Qualifiers.")
91
source 1..160699376 /organism="Rattus norvegicus" /mol_type="genomic DNA" /strain="BN/SsNHsdMCW" /db_xref="taxon:10116" /chromosome="X" CONTIG join(AABR03127247.1:1..2024,gap(50),AABR03121145.1:1..21813, gap(50),AABR03122703.1:1..11980,gap(50),AABR03123957.1:1..7435, gap(52),AABR03124244.1:1..6708,gap(50),AABR03123413.1:1..9129, gap(97),AABR03121097.1:1..22228,gap(50),AABR03124435.1:1..6221, gap(538),AABR03122840.1:1..11401,gap(50),AABR03126912.1:1..2386, gap(351),AABR03121226.1:1..20935,gap(234),AABR03120715.1:1..26654, gap(50),AABR03119488.1:1..60857,gap(50),AABR03125886.1:1..3719, gap(120),AABR03120800.1:1..25396,gap(121),AABR03123555.1:1..8676, gap(4037),AABR03123599.1:1..8539,gap(581),AABR03120940.1:1..23746, gap(285),AABR03119497.1:1..59935,gap(610),AABR03120908.1:1..24063, gap(50),AABR03121186.1:1..21258,gap(50),AABR03124660.1:1..5753, gap(50),AABR03125065.1:1..4968,gap(907),AABR03125825.1:1..3795, gap(50),AABR03127190.1:1..2096,gap(7811),AABR03125897.1:1..3700, gap(50),AABR03127480.1:1..1717,gap(447),AABR03127416.1:1..1801, source 1..160699376 /organism="Rattus norvegicus" /mol_type="genomic DNA" /strain="BN/SsNHsdMCW" /db_xref="taxon:10116" /chromosome="X" CONTIG join(AABR03127247.1:1..2024,gap(50),AABR03121145.1:1..21813, gap(50),AABR03122703.1:1..11980,gap(50),AABR03123957.1:1..7435, gap(52),AABR03124244.1:1..6708,gap(50),AABR03123413.1:1..9129, gap(97),AABR03121097.1:1..22228,gap(50),AABR03124435.1:1..6221, gap(538),AABR03122840.1:1..11401,gap(50),AABR03126912.1:1..2386, gap(351),AABR03121226.1:1..20935,gap(234),AABR03120715.1:1..26654, gap(50),AABR03119488.1:1..60857,gap(50),AABR03125886.1:1..3719, gap(120),AABR03120800.1:1..25396,gap(121),AABR03123555.1:1..8676, gap(4037),AABR03123599.1:1..8539,gap(581),AABR03120940.1:1..23746, gap(285),AABR03119497.1:1..59935,gap(610),AABR03120908.1:1..24063, gap(50),AABR03121186.1:1..21258,gap(50),AABR03124660.1:1..5753, gap(50),AABR03125065.1:1..4968,gap(907),AABR03125825.1:1..3795, gap(50),AABR03127190.1:1..2096,gap(7811),AABR03125897.1:1..3700, gap(50),AABR03127480.1:1..1717,gap(447),AABR03127416.1:1..1801,
,AABR : , gap(50),AABR : ,gap(50),AABR : , gap(52),AABR : ,gap(50),AABR : , gap(97),AABR : ,gap(50),AABR : , gap(538),AABR : ,gap(50),AABR : , gap(351),AABR : ,gap(234),AABR : , gap(50),AABR : ,gap(50),AABR : , gap(120),AABR : ,gap(121),AABR : , gap(4037),AABR : ,gap(581),AABR : , gap(285),AABR : ,gap(610),AABR : , gap(50),AABR : ,gap(50),AABR : , gap(50),AABR : ,gap(907),AABR : , gap(50),AABR : ,gap(7811),AABR : , gap(50),AABR : ,gap(447),AABR : , source /organism= Rattus norvegicus /mol_type= genomic DNA /strain= BN/SsNHsdMCW /db_xref= taxon:10116 /chromosome= X CONTIG join(AABR : ,gap(50),AABR : , gap(50),AABR : ,gap(50),AABR : , gap(52),AABR : ,gap(50),AABR : , gap(97),AABR : ,gap(50),AABR : , gap(538),AABR : ,gap(50),AABR : , gap(351),AABR : ,gap(234),AABR : , gap(50),AABR : ,gap(50),AABR : , gap(120),AABR : ,gap(121),AABR : , gap(4037),AABR : ,gap(581),AABR : , gap(285),AABR : ,gap(610),AABR : , gap(50),AABR : ,gap(50),AABR : , gap(50),AABR : ,gap(907),AABR : , gap(50),AABR : ,gap(7811),AABR : , gap(50),AABR : ,gap(447),AABR : ,")
92
Sequences NOT in GenBank WGS TPA SNPs SAGE tags RefSeq (Genomic, mRNA, or protein) Consensus sequences
 Consensus sequences")
93
What is UniProt? UniProt is a new protein sequence database that is the result of a merge from SWISS-PROT and PIR and is in great part funded by the NIH. It is the main distributed, annotated, and curated protein sequence database. Data in UniProt is primarily derived from coding sequence annotations in EMBL (GenBank/DDBJ) nucleic acid sequence data, but also from sequences in PIR and SP. UniProt is a Flat-File database just like EMBL and SwissProt http://www.pir.uniprot.org/ Bairoch et al., The Universal Protein Resource (UniProt) Nucl. Acids Res. 2005 33: D154-D159
 nucleic acid sequence data, but also from sequences in PIR and SP. UniProt is a Flat-File database just like EMBL and SwissProt Bairoch et al., The Universal Protein Resource (UniProt) Nucl. Acids Res : D154-D159.")
98
Swiss-ProtSwiss-Prot ID CYS3_YEAST STANDARD; PRT; 393 AA. AC P31373; DT 01-JUL-1993 (REL. 26, CREATED) DE CYSTATHIONINE GAMMA-LYASE (EC 4.4.1.1) (GAMMA-CYSTATHIONASE). GN CYS3 OR CYI1 OR STR1 OR YAL012W OR FUN35. OS TAXONOMY OC SACCHAROMYCETACEAE; SACCHAROMYCES. RX CITATION CC -!- CATALYTIC ACTIVITY: L-CYSTATHIONINE + H(2)O = L-CYSTEINE + CC NH(3) + 2-OXOBUTANOATE. CC -!- COFACTOR: PYRIDOXAL PHOSPHATE. CC -!- PATHWAY: FINAL STEP IN THE TRANS-SULFURATION PATHWAY SYNTHESIZING CC L-CYSTEINE FROM L-METHIONINE. CC -!- SUBUNIT: HOMOTETRAMER. CC -!- SUBCELLULAR LOCATION: CYTOPLASMIC. CC -!- SIMILARITY: BELONGS TO THE TRANS-SULFURATION ENZYMES FAMILY. CC -------------------------------------------------------------------------- CC DISCLAMOR CC -------------------------------------------------------------------------- DR DATABASE cross-reference KW CYSTEINE BIOSYNTHESIS; LYASE; PYRIDOXAL PHOSPHATE. FT INIT_MET 0 0 FT BINDING 203 203 PYRIDOXAL PHOSPHATE (BY SIMILARITY). SQ SEQUENCE 393 AA; 42411 MW; 55BA2771 CRC32; TLQESDKFAT KAIHAGEHVD VHGSVIEPIS LSTTFKQSSP ANPIGTYEYS RSQNPNRENL ERAVAALENA QYGLAFSSGS ATTATILQSL PQGSHAVSIG DVYGGTHRYF TKVANAHGVE TSFTNDLLND LPQLIKENTK LVWIETPTNP TLKVTDIQKV ADLIKKHAAG QDVILVVDNT FLSPYISNPL NFGADIVVHS ATKYINGHSD VVLGVLATNN KPLYERLQFL QNAIGAIPSP FDAWLTHRGL KTLHLRVRQA ALSANKIAEF LAADKENVVA VNYPGLKTHP NYDVVLKQHR DALGGGMISF RIKGGAEAAS KFASSTRLFT LAESLGGIES LLEVPAVMTH GGIPKEAREA SGVFDDLVRI SVGIEDTDDL LEDIKQALKQ ATN // ID CYS3_YEAST STANDARD; PRT; 393 AA. AC P31373; DT 01-JUL-1993 (REL. 26, CREATED) DT 01-JUL-1993 (REL. 26, LAST SEQUENCE UPDATE) DT 01-NOV-1995 (REL. 32, LAST ANNOTATION UPDATE) DE CYSTATHIONINE GAMMA-LYASE (EC 4.4.1.1) (GAMMA-CYSTATHIONASE). GN CYS3 OR CYI1 OR STR1 OR YAL012W OR FUN35. OS SACCHAROMYCES CEREVISIAE (BAKER'S YEAST). OC EUKARYOTA; FUNGI; ASCOMYCOTA; HEMIASCOMYCETES; SACCHAROMYCETALES; OC SACCHAROMYCETACEAE; SACCHAROMYCES. RN [1] RP SEQUENCE FROM N.A., AND PARTIAL SEQUENCE. RX MEDLINE; 92250430. [NCBI, ExPASy, Israel, Japan] RA ONO B.-I., TANAKA K., NAITO K., HEIKE C., SHINODA S., YAMAMOTO S., RA OHMORI S., OSHIMA T., TOH-E A.; RT "Cloning and characterization of the CYS3 (CYI1) gene of RT Saccharomyces cerevisiae."; RL J. BACTERIOL. 174:3339-3347(1992). RN [2] RP SEQUENCE FROM N.A., AND CHARACTERIZATION. RC STRAIN=DBY939; RX MEDLINE; 93328685. [NCBI, ExPASy, Israel, Japan] RA YAMAGATA S., D'ANDREA R.J., FUJISAKI S., ISAJI M., NAKAMURA K.; RT "Cloning and bacterial expression of the CYS3 gene encoding RT cystathionine gamma-lyase of Saccharomyces cerevisiae and the RT physicochemical and enzymatic properties of the protein."; RL J. BACTERIOL. 175:4800-4808(1993). RN [3] RP SEQUENCE FROM N.A. RC STRAIN=S288C / AB972; RX MEDLINE; 93289814. [NCBI, ExPASy, Israel, Japan] RA BARTON A.B., KABACK D.B., CLARK M.W., KENG T., OUELLETTE B.F.F., RA STORMS R.K., ZENG B., ZHONG W.W., FORTIN N., DELANEY S., BUSSEY H.; RT "Physical localization of yeast CYS3, a gene whose product resembles RT the rat gamma-cystathionase and Escherichia coli cystathionine gamma- RT synthase enzymes."; RL YEAST 9:363-369(1993). RN [4] RP SEQUENCE FROM N.A. RC STRAIN=S288C / AB972; RX MEDLINE; 93209532. [NCBI, ExPASy, Israel, Japan] RA OUELLETTE B.F.F., CLARK M.W., KENG T., STORMS R.K., ZHONG W.W., RA ZENG B., FORTIN N., DELANEY S., BARTON A.B., KABACK D.B., BUSSEY H.; RT "Sequencing of chromosome I from Saccharomyces cerevisiae: analysis RT of a 32 kb region between the LTE1 and SPO7 genes."; RL GENOME 36:32-42(1993). RN [5] RP SEQUENCE OF 1-18, AND CHARACTERIZATION. RX MEDLINE; 93289817. [NCBI, ExPASy, Israel, Japan] RA ONO B.-I., ISHII N., NAITO K., MIYOSHI S.-I., SHINODA S., YAMAMOTO S., RA OHMORI S.; RT "Cystathionine gamma-lyase of Saccharomyces cerevisiae: structural RT gene and cystathionine gamma-synthase activity."; RL YEAST 9:389-397(1993). CC -!- CATALYTIC ACTIVITY: L-CYSTATHIONINE + H(2)O = L-CYSTEINE + CC NH(3) + 2-OXOBUTANOATE. CC -!- COFACTOR: PYRIDOXAL PHOSPHATE. CC -!- PATHWAY: FINAL STEP IN THE TRANS-SULFURATION PATHWAY SYNTHESIZING CC L-CYSTEINE FROM L-METHIONINE. CC -!- SUBUNIT: HOMOTETRAMER. CC -!- SUBCELLULAR LOCATION: CYTOPLASMIC. CC -!- SIMILARITY: BELONGS TO THE TRANS-SULFURATION ENZYMES FAMILY. CC -------------------------------------------------------------------------- CC This SWISS-PROT entry is copyright. It is produced through a collaboration CC between the Swiss Institute of Bioinformatics and the EMBL outstation - CC the European Bioinformatics Institute. There are no restrictions on its CC use by non-profit institutions as long as its content is in no way CC modified and this statement is not removed. Usage by and for commercial CC entities requires a license agreement (See http://www.isb-sib.ch/announce/ CC or send an email to license@isb-sib.ch). CC -------------------------------------------------------------------------- DR EMBL; L05146; AAC04945.1; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR EMBL; L04459; AAA85217.1; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR EMBL; D14135; BAA03190.1; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR PIR; S31228; S31228. DR YEPD; 5280; -. DR SGD; L0000470; CYS3. [SGD / YPD] DR PFAM; PF01053; Cys_Met_Meta_PP; 1. DR PROSITE; PS00868; CYS_MET_METAB_PP; 1. DR DOMO; P31373. DR PRODOM [Domain structure / List of seq. sharing at least 1 domain] DR PROTOMAP; P31373. DR PRESAGE; P31373. DR SWISS-2DPAGE; GET REGION ON 2D PAGE. KW CYSTEINE BIOSYNTHESIS; LYASE; PYRIDOXAL PHOSPHATE. FT INIT_MET 0 0 FT BINDING 203 203 PYRIDOXAL PHOSPHATE (BY SIMILARITY). SQ SEQUENCE 393 AA; 42411 MW; 55BA2771 CRC32; TLQESDKFAT KAIHAGEHVD VHGSVIEPIS LSTTFKQSSP ANPIGTYEYS RSQNPNRENL ERAVAALENA QYGLAFSSGS ATTATILQSL PQGSHAVSIG DVYGGTHRYF TKVANAHGVE TSFTNDLLND LPQLIKENTK LVWIETPTNP TLKVTDIQKV ADLIKKHAAG QDVILVVDNT FLSPYISNPL NFGADIVVHS ATKYINGHSD VVLGVLATNN KPLYERLQFL QNAIGAIPSP FDAWLTHRGL KTLHLRVRQA ALSANKIAEF LAADKENVVA VNYPGLKTHP NYDVVLKQHR DALGGGMISF RIKGGAEAAS KFASSTRLFT LAESLGGIES LLEVPAVMTH GGIPKEAREA SGVFDDLVRI SVGIEDTDDL LEDIKQALKQ ATN //
 DE CYSTATHIONINE GAMMA-LYASE (EC ) (GAMMA-CYSTATHIONASE). GN CYS3 OR CYI1 OR STR1 OR YAL012W OR FUN35. OS TAXONOMY OC SACCHAROMYCETACEAE; SACCHAROMYCES. RX CITATION CC -!- CATALYTIC ACTIVITY: L-CYSTATHIONINE + H(2)O = L-CYSTEINE + CC NH(3) + 2-OXOBUTANOATE. CC -!- COFACTOR: PYRIDOXAL PHOSPHATE. CC -!- PATHWAY: FINAL STEP IN THE TRANS-SULFURATION PATHWAY SYNTHESIZING CC L-CYSTEINE FROM L-METHIONINE. CC -!- SUBUNIT: HOMOTETRAMER. CC -!- SUBCELLULAR LOCATION: CYTOPLASMIC. CC -!- SIMILARITY: BELONGS TO THE TRANS-SULFURATION ENZYMES FAMILY. CC CC DISCLAMOR CC DR DATABASE cross-reference KW CYSTEINE BIOSYNTHESIS; LYASE; PYRIDOXAL PHOSPHATE. FT INIT_MET 0 0 FT BINDING PYRIDOXAL PHOSPHATE (BY SIMILARITY). SQ SEQUENCE 393 AA; MW; 55BA2771 CRC32; TLQESDKFAT KAIHAGEHVD VHGSVIEPIS LSTTFKQSSP ANPIGTYEYS RSQNPNRENL ERAVAALENA QYGLAFSSGS ATTATILQSL PQGSHAVSIG DVYGGTHRYF TKVANAHGVE TSFTNDLLND LPQLIKENTK LVWIETPTNP TLKVTDIQKV ADLIKKHAAG QDVILVVDNT FLSPYISNPL NFGADIVVHS ATKYINGHSD VVLGVLATNN KPLYERLQFL QNAIGAIPSP FDAWLTHRGL KTLHLRVRQA ALSANKIAEF LAADKENVVA VNYPGLKTHP NYDVVLKQHR DALGGGMISF RIKGGAEAAS KFASSTRLFT LAESLGGIES LLEVPAVMTH GGIPKEAREA SGVFDDLVRI SVGIEDTDDL LEDIKQALKQ ATN // ID CYS3_YEAST STANDARD; PRT; 393 AA. AC P31373; DT 01-JUL-1993 (REL. 26, CREATED) DT 01-JUL-1993 (REL. 26, LAST SEQUENCE UPDATE) DT 01-NOV-1995 (REL. 32, LAST ANNOTATION UPDATE) DE CYSTATHIONINE GAMMA-LYASE (EC ) (GAMMA-CYSTATHIONASE). GN CYS3 OR CYI1 OR STR1 OR YAL012W OR FUN35. OS SACCHAROMYCES CEREVISIAE (BAKER S YEAST). OC EUKARYOTA; FUNGI; ASCOMYCOTA; HEMIASCOMYCETES; SACCHAROMYCETALES; OC SACCHAROMYCETACEAE; SACCHAROMYCES. RN [1] RP SEQUENCE FROM N.A., AND PARTIAL SEQUENCE. RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA ONO B.-I., TANAKA K., NAITO K., HEIKE C., SHINODA S., YAMAMOTO S., RA OHMORI S., OSHIMA T., TOH-E A.; RT Cloning and characterization of the CYS3 (CYI1) gene of RT Saccharomyces cerevisiae. ; RL J. BACTERIOL. 174: (1992). RN [2] RP SEQUENCE FROM N.A., AND CHARACTERIZATION. RC STRAIN=DBY939; RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA YAMAGATA S., D ANDREA R.J., FUJISAKI S., ISAJI M., NAKAMURA K.; RT Cloning and bacterial expression of the CYS3 gene encoding RT cystathionine gamma-lyase of Saccharomyces cerevisiae and the RT physicochemical and enzymatic properties of the protein. ; RL J. BACTERIOL. 175: (1993). RN [3] RP SEQUENCE FROM N.A. RC STRAIN=S288C / AB972; RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA BARTON A.B., KABACK D.B., CLARK M.W., KENG T., OUELLETTE B.F.F., RA STORMS R.K., ZENG B., ZHONG W.W., FORTIN N., DELANEY S., BUSSEY H.; RT Physical localization of yeast CYS3, a gene whose product resembles RT the rat gamma-cystathionase and Escherichia coli cystathionine gamma- RT synthase enzymes. ; RL YEAST 9: (1993). RN [4] RP SEQUENCE FROM N.A. RC STRAIN=S288C / AB972; RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA OUELLETTE B.F.F., CLARK M.W., KENG T., STORMS R.K., ZHONG W.W., RA ZENG B., FORTIN N., DELANEY S., BARTON A.B., KABACK D.B., BUSSEY H.; RT Sequencing of chromosome I from Saccharomyces cerevisiae: analysis RT of a 32 kb region between the LTE1 and SPO7 genes. ; RL GENOME 36:32-42(1993). RN [5] RP SEQUENCE OF 1-18, AND CHARACTERIZATION. RX MEDLINE; [NCBI, ExPASy, Israel, Japan] RA ONO B.-I., ISHII N., NAITO K., MIYOSHI S.-I., SHINODA S., YAMAMOTO S., RA OHMORI S.; RT Cystathionine gamma-lyase of Saccharomyces cerevisiae: structural RT gene and cystathionine gamma-synthase activity. ; RL YEAST 9: (1993). CC -!- CATALYTIC ACTIVITY: L-CYSTATHIONINE + H(2)O = L-CYSTEINE + CC NH(3) + 2-OXOBUTANOATE. CC -!- COFACTOR: PYRIDOXAL PHOSPHATE. CC -!- PATHWAY: FINAL STEP IN THE TRANS-SULFURATION PATHWAY SYNTHESIZING CC L-CYSTEINE FROM L-METHIONINE. CC -!- SUBUNIT: HOMOTETRAMER. CC -!- SUBCELLULAR LOCATION: CYTOPLASMIC. CC -!- SIMILARITY: BELONGS TO THE TRANS-SULFURATION ENZYMES FAMILY. CC CC This SWISS-PROT entry is copyright. It is produced through a collaboration CC between the Swiss Institute of Bioinformatics and the EMBL outstation - CC the European Bioinformatics Institute. There are no restrictions on its CC use by non-profit institutions as long as its content is in no way CC modified and this statement is not removed. Usage by and for commercial CC entities requires a license agreement (See CC or send an to CC DR EMBL; L05146; AAC ; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR EMBL; L04459; AAA ; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR EMBL; D14135; BAA ; -. [EMBL / GenBank / DDBJ] [CoDingSequence] DR PIR; S31228; S DR YEPD; 5280; -. DR SGD; L ; CYS3. [SGD / YPD] DR PFAM; PF01053; Cys_Met_Meta_PP; 1. DR PROSITE; PS00868; CYS_MET_METAB_PP; 1. DR DOMO; P DR PRODOM [Domain structure / List of seq. sharing at least 1 domain] DR PROTOMAP; P DR PRESAGE; P DR SWISS-2DPAGE; GET REGION ON 2D PAGE. KW CYSTEINE BIOSYNTHESIS; LYASE; PYRIDOXAL PHOSPHATE. FT INIT_MET 0 0 FT BINDING PYRIDOXAL PHOSPHATE (BY SIMILARITY). SQ SEQUENCE 393 AA; MW; 55BA2771 CRC32; TLQESDKFAT KAIHAGEHVD VHGSVIEPIS LSTTFKQSSP ANPIGTYEYS RSQNPNRENL ERAVAALENA QYGLAFSSGS ATTATILQSL PQGSHAVSIG DVYGGTHRYF TKVANAHGVE TSFTNDLLND LPQLIKENTK LVWIETPTNP TLKVTDIQKV ADLIKKHAAG QDVILVVDNT FLSPYISNPL NFGADIVVHS ATKYINGHSD VVLGVLATNN KPLYERLQFL QNAIGAIPSP FDAWLTHRGL KTLHLRVRQA ALSANKIAEF LAADKENVVA VNYPGLKTHP NYDVVLKQHR DALGGGMISF RIKGGAEAAS KFASSTRLFT LAESLGGIES LLEVPAVMTH GGIPKEAREA SGVFDDLVRI SVGIEDTDDL LEDIKQALKQ ATN //.")
99
UniProtUniProt UniProt incorporates: Function of the protein Post-translational modification Domains and sites. Secondary structure. Quaternary structure. Similarities to other proteins; Diseases associated with deficiencies in the protein Sequence conflicts, variants, etc.

100
In closing... Often only use FASTA files (eg for BLAST) GBFF are simply human readable versions of these records GBFF have become a vehicle for a lot more information than they where meant to do Keep in mind that GenBank is DNA centric and is a poor vehicle for protein and mRNA expression/interaction information
 GBFF are simply human readable versions of these records GBFF have become a vehicle for a lot more information than they where meant to do Keep in mind that GenBank is DNA centric and is a poor vehicle for protein and mRNA expression/interaction information.")
101
In closing (cont’d)... Able to recognize various data formats, and know what their primary use is. Know, understand and utilize all types of sequence identifiers. Know and understand various feature types present in the GenBank flat files. Know and understand the various GenBank divisions.

105
Proteins DatabaseDescriptionnrAll non-redundant GenBank CDS translations+PDB+SwissProt+PIR+PRF monthAll new or revised GenBank CDS translation+PDB+SwissProt+PIR released in the last 30 days. swissprotThe last major release of the SWISS-PROT protein sequence database (no updates). These are uploaded to our system when they are received from EMBL.patentsProtein sequences derived from the Patent division of GenBank.yeastYeast (Saccharomyces cerevisiae) protein sequences. This database is not to be confused with a listing of all Yeast protein sequences. It is a database of the protein translations of the Yeast complete genome.E. coliE. coli (Escherichia coli) genomic CDS translations.pdbSequences derived from the 3-dimensional structure Brookhaven Protein Data Bank.kabat [kabatpro]Kabat's database of sequences of immunological interest. For more information http://immuno.bme.nwu.edu/aluTranslations of select Alu repeats from REPBASE, suitable for masking Alu repeats from query sequences. It is available at ftp://ncbi.nlm.nih.gov/pub/jmc/alu. See "Alu alert" by Claverie and Makalowski, Nature vol. 371, page 752 (1994). http://immuno.bme.nwu.edu/ftp://ncbi.nlm.nih.gov/pub/jmc/aluClaverie and Makalowski, Nature vol. 371, page 752 (1994)
. These are uploaded to our system when they are received from EMBL.patentsProtein sequences derived from the Patent division of GenBank.yeastYeast (Saccharomyces cerevisiae) protein sequences. This database is not to be confused with a listing of all Yeast protein sequences. It is a database of the protein translations of the Yeast complete genome.E. coliE. coli (Escherichia coli) genomic CDS translations.pdbSequences derived from the 3-dimensional structure Brookhaven Protein Data Bank.kabat [kabatpro]Kabat s database of sequences of immunological interest. For more information of select Alu repeats from REPBASE, suitable for masking Alu repeats from query sequences. It is available at ftp://ncbi.nlm.nih.gov/pub/jmc/alu. See Alu alert by Claverie and Makalowski, Nature vol. 371, page 752 (1994). and Makalowski, Nature vol. 371, page 752 (1994).")
107
Box 1. Some fields used to index Entrez Gene. A comprehensive list, with examples, is maintained in Entrez Gene's help documentation.help documentation Field name ChromosomeCreation dateDefault map locationDisease or phenotypeDomain nameEC/RN numberGene nameGene Ontology (GO terms and values)Gene/protein nameMIMModification DateNucleotide AccessionNucleotide UIDNucleotide or protein AccessionOrganism
Gene/protein nameMIMModification DateNucleotide AccessionNucleotide UIDNucleotide or protein AccessionOrganism.")
109
Databases Nucleotide sequences: DDBJ/EMBL/NCBI store Genomic/cDNAs/ESTs. Protein sequences: Uniprot: swissprot (manually curated) and trembl (automated annotation). Accession numbers (a unique number or combination of letters and numbers assigned to each record in a database) identify these sequences. E.g. (AL034553). Protein domain databases: Interpro~pfam/prints/prosite…..
 and trembl (automated annotation). Accession numbers (a unique number or combination of letters and numbers assigned to each record in a database) identify these sequences. E.g. (AL034553). Protein domain databases: Interpro~pfam/prints/prosite…...")
110
Information is mirrored daily between DDBJ, GenBank and EMBL.

111
Abbreviations found in the EMBL flat file:

120
Summary You have been introduced to: A number of different databases that contain DNA and Protein sequences. Identifying sequences by their accession numbers. The structure and format of flat files that are contained in these databases. Databases available at DDBJ, EBI, NCBI. Sequence/Data retrieval using SRS and Entrez including Ref_Seqs, the gold standard annotation. Interpro. Integrated Protein resource for families, domains and sites. Expasy. Advanced protein analysis e.g. prediction of tertiary structures.

123
Databases Biological Data – Biological Databases Sequences Maps Clones Organisms Structures Motifs Cells Functions Pathways Phenotypes Papers Genomes

124
Swissprot Annotation ID AMPA_CHLTR STANDARD; PRT; 499 AA. AC O84049; DT 15-FEB-2000 (Rel. 39, Created) DT 15-FEB-2000 (Rel. 39, Last sequence update) DT 15-FEB-2000 (Rel. 39, Last annotation update) DE PROBABLE CYTOSOL AMINOPEPTIDASE (EC 3.4.11.1) DE (LEUCINE AMINOPEPTIDASE) DE (LAP). Probable - Putative - Potential CC -!- CATALYTIC ACTIVITY: AMINOACYL-PEPTIDE + H(2)O = AMINO ACID + CC PEPTIDE. CC -!- SIMILARITY: BELONGS TO PEPTIDASE FAMILY M17; ALSO KNOWN AS THE CC CYTOSOL AMINOPEPTIDASE FAMILY. FT METAL 263 263 MANGANESE OR ZINC (BY SIMILARITY). FT METAL 268 268 MANGANESE OR ZINC (BY SIMILARITY). FT ACT_SITE 275 275 POTENTIAL.
 DT 15-FEB-2000 (Rel. 39, Last sequence update) DT 15-FEB-2000 (Rel. 39, Last annotation update) DE PROBABLE CYTOSOL AMINOPEPTIDASE (EC ) DE (LEUCINE AMINOPEPTIDASE) DE (LAP). Probable - Putative - Potential CC -!- CATALYTIC ACTIVITY: AMINOACYL-PEPTIDE + H(2)O = AMINO ACID + CC PEPTIDE. CC -!- SIMILARITY: BELONGS TO PEPTIDASE FAMILY M17; ALSO KNOWN AS THE CC CYTOSOL AMINOPEPTIDASE FAMILY. FT METAL MANGANESE OR ZINC (BY SIMILARITY). FT METAL MANGANESE OR ZINC (BY SIMILARITY). FT ACT_SITE POTENTIAL..")
125
Other Databases Rebase - the restriction enzyme database Prosite - protein functional sites (pattern and profiles) PDB - protein structures OMIM - Online Mendelian Inheritance in Man
 PDB - protein structures OMIM - Online Mendelian Inheritance in Man")
126
Protein Domain Databases Prosite Prints Blocks Pfam Prodom INTERPRO Protein Analysis Short conserved patterns (+ profiles) Fingerprints (aligned unweighted motifs) Blocks (aligned weighted motifs) Domain HMMs Domain multiple alignments
 Fingerprints (aligned unweighted motifs) Blocks (aligned weighted motifs) Domain HMMs Domain multiple alignments")
127
Databases Human Genome NCBI Human_assembled LocusLink Refseq Unigene EBI EnsEMBL EnsEMBL_cDNA EnsEMBL_prot

128
RefSeq and LocusLink

129
NCBI Contig Assembly Building the contig: - draft and finished data from Genbank - screen for contaminating sequences, - the clone layout using sequence overlap - Overlapping sequences are then merged together to form a single contiguous stretch called a meld. A contig may have several melds. Annotate features - variation, sequence tagged sites, FISH mapped clone regions, known and predicted genes, and gene models are annotated. Each gene provides connections to LocusLink. Provide dataset: New RefSeq-Sequences and sequences: NT_ (contig) XM_ (model mRNA) XP_ (model protein)
 XM_ (model mRNA) XP_ (model protein).")
130
Refseq and Locuslink 2. An appropriate representative for a gene. This initial sequence information, stored in the LocusLink database as the Seed sequence. RefSeq: 3. The Seed sequence is used in BLAST BLAST results are sorted to identify the longest mRNA sequence that maintains 100% sequence identity with the seed sequence through the coding region. 4. Sequences identified in step 3 with a full-length coding region are used to create the predicted and provisional RefSeq records. These RefSeq records are generated via an automatic process including: Additional publications, Aliases, LocusID number, MIM number, Map information, Official gene symbol and name

131
LocuslinkLocuslink LocusLink provides a single query interface to curated sequence and descriptive information about genetic loci. It presents information on official nomenclature, aliases, sequence accessions, phenotypes, EC numbers, MIM numbers, UniGene clusters, homology, map locations, and related web sites.

132
Ensembl (EBI + Sanger) Ensembl 0.80 covers 94% of known genes. Update: 14-02-2001 Confirmed genes: 25790 Predicted genes: 390090 Confirmed exons: 169429 Predicted exon 1129720 Transcripts: 29691 Contigs: 412609 Sequences: 30445 Base Pairs: 4409077670 Ensembl version 11 (march 2003) nine species with new data - 24,847 Genes containing 37,347 Transcripts - covers over 95% of known genes - "EST genes" with a total of 282908 transcripts
 nine species with new data - 24,847 Genes containing 37,347 Transcripts - covers over 95% of known genes - EST genes with a total of transcripts.")
133
EnsemblEnsembl

134
EnsembleEnsemble

135
Database Annotation Search Tools ENTREZ (NCBI) SRS (now LION, was EBI)
 SRS (now LION, was EBI)")
136
SRS Sequence Retrieval System SRS[tm] is a data retrieval system that integrates heterogeneous databanks in molecular biology and genome analysis. There are currently several dozen servers world-wide that provide access to over 300 different databanks via the World Wide Web. Dr Thure Etzold, Director of Lion Bioscience Ltd, is also a group leader at the European Bioinformatics Institute, Hinxton, UK.
![SRS Sequence Retrieval System SRS[tm] is a data retrieval system that integrates heterogeneous databanks in molecular biology and genome analysis.](http://images.slideplayer.com/15/4811415/slides/slide_136.jpg "There are currently several dozen servers world-wide that provide access to over 300 different databanks via the World Wide Web. Dr Thure Etzold, Director of Lion Bioscience Ltd, is also a group leader at the European Bioinformatics Institute, Hinxton, UK..")
139
SRS and Common Data Manipulation Paul Gordon

140
Just as you can retrieve sequences from NCBI it is possible to obtain them from CBR (with EMBL, etc. too) CBR uses the Sequence Retrieval System, or SRS SRS offers a web-based or command- line interface for obtaining sequences CBR databases are updated nightly, this of course includes re-indexing all updated SRS databases CBR Sequence Retrieval
 CBR uses the Sequence Retrieval System, or SRS SRS offers a web-based or command- line interface for obtaining sequences CBR databases are updated nightly, this of course includes re-indexing all updated SRS databases CBR Sequence Retrieval.")
141
SRSSRS Reasons for using SRS: –Look up the reference for a sequence –Check an entire entry & related data –Saving sequences for processing Main ways to retrieve data: –Search for the ID of a sequence –Search for specific text anywhere in entries –Search for sequences that satisfy certain parameters

142
Web-Based SRS The web-based interface for SRS is very flexible and convenient offering a number ways to access and view data such as: –searching individual or multiple databanks in a number of ways –searching based on provided criteria: the number of fields can be quite extensive –viewing data in a format specified by the user –using previous query results to refine data –saving the data in multiple formats –temporary and permanent sessions

143
Searching Databanks It is possible, in the databanks section, by clicking a database link to get info about that databank and to search that databank by its indexed fields After clicking start, choose desired databanks from databank groups choosing how to search: –quick search based on one query term against all database fields –standard query form –extended query form

144
ViewsViews SRS allows a user to customize the look of data found after a search operation A number of options are available from a dropdown listbox under the perform operation section of a search result page Under the views section of SRS it is possible for the user to create views tailored to their needs

145
Using Previous Results In the results section of SRS are the sequence sets from previous queries Information is provided about each query result set so it is to distinguish between sets Operations such as AND, OR, and BUTNOT are available and can be used to refine and combine the data of multiple query sets

146
Saving Data SRS allows the user to then save the results of a search by choosing the format of the saved sequences A number of sequence formats are available depending on the data The save operation is set up under the perform operations section of the results page in a similar manner to the view operation

147
SessionsSessions There are two types of SRS sessions : temporary and permanent A temporary session starts from the opening screen when a user clicks the start button. Once a user closes the browser searches and results are lost. A permanent session is started by logging in via the sessions button on the opening page. A permanent session is saved on the CBR web-server and can be revisited at any time.

148
Command-line vs.Web-based SRS As previously mentioned each interface has its advantages and disadvantages Advantages for Web-based SRS –Allows formatted views of the data –Quick searches are easy –Permanent sessions allow the user to continue what they were doing –No debugging search strings

149
Command-line vs. Web- based SRS Advantages of command-line SRS –Allows the user to incorporate SRS searches in a program –Even more powerful searches –Save sequences on the CBR server instead of on your desktop machine –Easier to save very large queries, as browsers sometimes time out (e.g. retrieve all E. coli protein entries)
.")
150
Simplified Entry Retrieval A program called getbyid is a wrapper to SRS which lets you retrieve entries simply, similar to dbfetch in GCG, but more inclusive Allows access to all of the data sources used in the non-redundant protein database except PRF, so protein lookup is easy. Be careful to escape identifiers such as ‘gi|10000389’ Command line usage: getbyid [-f (asta format)] [sequence_id/acc]…
] [sequence_id/acc]….")
151
ReadSeqReadSeq Readseq is a command-line program that will convert multi-sequence, multi-format nucleic/protein data files to a desired format data file Readseq is designed for smaller data files Typical readseq command: readseq -f8 -a -ooutfile infile

152
FormatdbFormatdb Formatdb will take fasta input files and index the sequences The index files are in blast format allowing a user to do a blast search against the newly created indices To produce a blast database type: formatdb -i infile -p ’T/F input is protein’ -o T

153
Aims Overview of sequence production. Acquaint you with different file formats and associated annotations. Introduce different nucleotide and protein databases. Show how to access different genomic data from a variety of databases, using SRS and Entrez.

154
Data Jungle sequencing information molecular biology physiology genetics toxicology medicine structural biology gene expression

155
RequirementsRequirements The system must integrate various types of data seamlessly. The system must provide a uniform user interface. The system must be able to scale. Must be easy to maintain and update Must grow with new data type needs.

156
SRS history 1990 - Main author Dr. Thure Etzold –Development started in EMBL, Heidelberg 1997 –Moved to EBI in Cambridge. Development work was supported by various grants amongst others from the EMBnet. 1998 –Etzold and his group join Lion Biosciences AG an offspin of the EMBL.

157
What is SRS(1/2) Read-only data warehouse. –It’s raw working material is text (flatfile databases - EMBL, Swiss-Prot, MEDLINE, HTML, XML files, etc…) Uses context parsers which are word oriented: ‘glutathione transferase’ indexes as ‘glutathione’ + ‘transferase’ –it is not a ‘free text search’ engine!
 Uses context parsers which are word oriented: ‘glutathione transferase’ indexes as ‘glutathione’ + ‘transferase’ –it is not a ‘free text search’ engine!.")
158
What is SRS(2/2) Enables linking between databases as these share primary and secondary identifiers : SWISS-PROT EMBL PDB InterPro PROSITE PFAM BLOCKS
 Enables linking between databases as these share primary and secondary identifiers : SWISS-PROT EMBL PDB InterPro PROSITE PFAM BLOCKS")
159
SRS Linking Linking is possible because of the presence of cross-reference information: –DR records in Swiss-Prot & EMBL –RX records from Swiss-Prot and EMBL to MEDLINE and PubMed.

160
SRS Linking A1 A2 A3 A4 A5 A B1 B2 B3 B4 B B2 B3 B4 A < B B > A A1 A2 A3 A4 ID A1 DR B3 ID B3 DR A1 DR A2 A > B B < A Queries: Link indexing

161
Main advantage of SRS linking ABC Direct link from ‘A’ to ‘B’Direct link from ‘B’ to ‘C’ Multi-step link from ‘A’ to ‘C’ An important thing to note is that links are bi-directional: If (‘A’ to ‘B’) exist then (‘B’ to ‘A’) do as well. And (‘C’ to ‘A’) as well...
 as well....")
162
Library network

163
Some queries using links EMBL > Swissprot proteins encoded by genes EMBL < Swissprot genes coding for proteins Swissprot < EPD all eukaryotic proteins for which the promoter is further characterised Swissprot > Prosite > Swissprot a single protein is expanded by all members of its family

164
Standard queries Queries in SRS are done at the indexed word level: –Need a list of all ‘human glutathione transferases’: query takes the form of: –find all human sequences –find all entries with ‘glutathione’ –find all entries with ‘transferase’ –SRS returns the intersection of all of the above.

165
Query operators (AND -&, OR -|, BUTNOT -!) Query: ‘human glutathione tranferase’ AND ‘human & glutathione & transferase’ OR ‘human | glutathione | transferase’ BUTNOT ‘human ! glutathione ! transferase’

166
EMBL HUMAN glutathione transferase Human & glutathione & transferase Human & transferase ! glutathione Glutathione & transferase ! human

167
The SRS user interfaces

168
Two interfaces Command line interface: –getz runs from the UNIX command line. WWW interface –wgetz runs from a httpd server.

169
getzgetz Getz provides access to all library functions within SRS: –Basic syntax for getz: getz -{function} ‘[libname-{indexname}:entry]’ –examples: »getz -info embl # displays info of embl »getz -e ‘[embl-id:hscfos]’ # retrieves HSCFOS »getz ‘[embl-datecreated#19980101:20010301]’
![getzgetz Getz provides access to all library functions within SRS: –Basic syntax for getz: getz -{function} ‘[libname-{indexname}:entry]’ –examples: »getz -info embl # displays info of embl »getz -e ‘[embl-id:hscfos]’ # retrieves HSCFOS »getz ‘[embl-datecreated# : ]’](http://images.slideplayer.com/15/4811415/slides/slide_169.jpg "getzgetz Getz provides access to all library functions within SRS: –Basic syntax for getz: getz -{function} ‘[libname-{indexname}:entry]’ –examples: »getz -info embl # displays info of embl »getz -e ‘[embl-id:hscfos]’ # retrieves HSCFOS »getz ‘[embl-datecreated# : ]’")
170
getzgetz Getz is very useful in a production environment where an entry is required for further processing from the command line. –UNIX examples: Need a restriction map of ‘hscfos’: –getz -e ‘[embl-id:hscfos]’ | tacg -s Need a fasta formatted version of hscfos: –getz -view FastaSeqs ‘[embl-id:hscfos]’

171
wgetzwgetz All the functionality of getz exists in wgetz. Difference is that wgetz works on the WWW - No need to worry about UNIX!!! Wgetz writes the HTML for all srs server pages.

173
Library groupsLibrary groups Libraries Query FormsWorkbenches

174
Query Fields Field Selection

175
HITS SRS QueryoperationsViews

176
Entry View

177
My queries Listing results

178
Creating Views Databases involved in the viewFields definition in the new View

179
Using the new view on a query

180
SRS applications(1/2) SRS not only works with ‘databases’ A fasta or blast result file can be considered by SRS as a database as well. Stand-alone application results can be linked to SRS libraries (i.e. blast, fasta, interproscan, results to EMBL, UniProt, etc.)
.")
181
SRS applications (2/2) Permit the user to carry on real analysis on the databases. –Mostly sequence databases Results of the analysis session are stored for max. 24 hours unless the session is kept alive. Recommend the use of Permanent sessions.

182
There are over 150 applications

183
SRS indices & databases

184
SRS indexing SRS indexes database records using a ‘word by word’ approach. –DE Human glutathione transferase –The SRS description index will contain terms ‘human’, ‘glutathione’ and ‘transferase’. Searches are restricted to the above terms.

185
Overview of SRS indices

186
Browsing SRS indexes

187
EMBLEMBL ID AF010316 standard; RNA; HUM; 1729 BP. XX AC AF010316; XX SV AF010316.1 XX DT 29-SEP-1997 (Rel. 52, Created) DT 03-MAR-2000 (Rel. 62, Last updated, Version 5) XX DE Homo sapiens Pig12 (PIG12) mRNA, complete cds. XX KW. XX OS Homo sapiens (human) OC Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; OC Eutheria; Primates; Catarrhini; Hominidae; Homo. XX RN [1] RP 1-1729 RX MEDLINE; 97449378. RA Polyak K., Xia Y., Zweier J.L., Kinzler K.W., Vogelstein B.; RT "A model for p53-induced apoptosis"; RL Nature 389(6648):300-305(1997). XX RN [2] RP 1-1729 RA Polyak K., Xia Y., Zweier J.L., Kinzler K.W., Vogelstein B.; RT ; RL Submitted (27-JUN-1997) to the EMBL/GenBank/DDBJ databases. RL Oncology, Johns Hopkins Oncology Center, 424. N. Bond St., Baltimore, MD RL 21231, USA XX DR SWISS-PROT; O14684; PTGE_HUMAN. XX
 DT 03-MAR-2000 (Rel. 62, Last updated, Version 5) XX DE Homo sapiens Pig12 (PIG12) mRNA, complete cds. XX KW. XX OS Homo sapiens (human) OC Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; OC Eutheria; Primates; Catarrhini; Hominidae; Homo. XX RN [1] RP RX MEDLINE; RA Polyak K., Xia Y., Zweier J.L., Kinzler K.W., Vogelstein B.; RT A model for p53-induced apoptosis ; RL Nature 389(6648): (1997). XX RN [2] RP RA Polyak K., Xia Y., Zweier J.L., Kinzler K.W., Vogelstein B.; RT ; RL Submitted (27-JUN-1997) to the EMBL/GenBank/DDBJ databases. RL Oncology, Johns Hopkins Oncology Center, 424. N. Bond St., Baltimore, MD RL 21231, USA XX DR SWISS-PROT; O14684; PTGE_HUMAN. XX.")
188
GenBankGenBank LOCUS AF010316 1729 bp mRNA PRI 09-JAN-1998 DEFINITION Homo sapiens Pig12 (PIG12) mRNA, complete cds. ACCESSION AF010316 VERSION AF010316.1 GI:2415307 KEYWORDS. SOURCE human. ORGANISM Homo sapiens Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Homo. REFERENCE 1 (bases 1 to 1729) AUTHORS Polyak,K., Xia,Y., Zweier,J.L., Kinzler,K.W. and Vogelstein,B. TITLE A model for p53-induced apoptosis JOURNAL Nature 389 (6648), 300-305 (1997) MEDLINE 97449378 REFERENCE 2 (bases 1 to 1729) AUTHORS Polyak,K., Xia,Y., Zweier,J.L., Kinzler,K.W. and Vogelstein,B. TITLE Direct Submission JOURNAL Submitted (27-JUN-1997) Oncology, Johns Hopkins Oncology Center, 424. N. Bond St., Baltimore, MD 21231, USA
 AUTHORS Polyak,K., Xia,Y., Zweier,J.L., Kinzler,K.W. and Vogelstein,B. TITLE A model for p53-induced apoptosis JOURNAL Nature 389 (6648), (1997) MEDLINE REFERENCE 2 (bases 1 to 1729) AUTHORS Polyak,K., Xia,Y., Zweier,J.L., Kinzler,K.W. and Vogelstein,B. TITLE Direct Submission JOURNAL Submitted (27-JUN-1997) Oncology, Johns Hopkins Oncology Center, 424. N. Bond St., Baltimore, MD 21231, USA.")
189
Swiss-ProtSwiss-Prot ID PTGE_HUMAN STANDARD; PRT; 152 AA. AC O14684; O14900; DT 30-MAY-2000 (Rel. 39, Created) DT 30-MAY-2000 (Rel. 39, Last sequence update) DT 01-OCT-2000 (Rel. 40, Last annotation update) DE PROSTAGLANDIN E SYNTHASE (MICROSOMAL GLUTATHIONE S-TRANSFERASE 1-LIKE DE 1) (MGST1-L1) (P53-INDUCED APOPTOSIS PROTEIN 12). GN PTGES OR MGST1L1 OR PIG12. OS Homo sapiens (Human). OC Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; OC Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Homo. OX NCBI_TaxID=9606; RN [1] RP SEQUENCE FROM N.A. RC TISSUE=COLON CANCER; RX MEDLINE=97449378; PubMed=9305847; RA Polyak K., Xia Y., Zweier J.L., Kinzler K.W., Vogelstein B.; RT "A model for p53-induced apoptosis."; RL Nature 389:300-306(1997). RN [2] RP SEQUENCE FROM N.A. RA Jakobsson P.-J., Mancini J.A., Ford-Hutchinson A.W.; RT "Human microsomal glutathione S-transferase 1-like 1 (MGST1L1)."; RL Submitted (OCT-1997) to the EMBL/GenBank/DDBJ databases. CC -!- SUBCELLULAR LOCATION: INTEGRAL MEMBRANE PROTEIN (POTENTIAL). CC -!- SIMILARITY: BELONGS TO THE MAPEG FAMILY. CC -------------------------------------------------------------------------- CC This SWISS-PROT entry is copyright. It is produced through a collaboration CC between the Swiss Institute of Bioinformatics and the EMBL outstation - CC the European Bioinformatics Institute. There are no restrictions on its CC use by non-profit institutions as long as its content is in no way CC modified and this statement is not removed. Usage by and for commercial CC entities requires a license agreement (See http://www.isb-sib.ch/announce/ CC or send an email to license@isb-sib.ch). CC -------------------------------------------------------------------------- DR EMBL; AF010316; AAC39534.1; -. DR EMBL; AF027740; AAB82299.1; -. DR InterPro; IPR001129; -. DR Pfam; PF01124; MAPEG; 1. KW Transmembrane. FT TRANSMEM 13 33 POTENTIAL. FT TRANSMEM 79 99 POTENTIAL. FT CONFLICT 55 55 G -> GG (IN REF. 1). SQ SEQUENCE 152 AA; 17102 MW; BF9B9ED81CA67A3D CRC64; MPAHSLVMSS PALPAFLLCS TLLVIKMYVV AIITGQVRLR KKAFANPEDA LRHGGPQYCR SDPDVERCLR AHRNDMETIY PFLFLGFVYS FLGPNPFVAW MHFLVFLVGR VAHTVAYLGK LRAPIRSVTY TLAQLPCASM ALQILWEAAR HL //
 DT 30-MAY-2000 (Rel. 39, Last sequence update) DT 01-OCT-2000 (Rel. 40, Last annotation update) DE PROSTAGLANDIN E SYNTHASE (MICROSOMAL GLUTATHIONE S-TRANSFERASE 1-LIKE DE 1) (MGST1-L1) (P53-INDUCED APOPTOSIS PROTEIN 12). GN PTGES OR MGST1L1 OR PIG12. OS Homo sapiens (Human). OC Eukaryota; Metazoa; Chordata; Craniata; Vertebrata; Euteleostomi; OC Mammalia; Eutheria; Primates; Catarrhini; Hominidae; Homo. OX NCBI_TaxID=9606; RN [1] RP SEQUENCE FROM N.A. RC TISSUE=COLON CANCER; RX MEDLINE= ; PubMed= ; RA Polyak K., Xia Y., Zweier J.L., Kinzler K.W., Vogelstein B.; RT A model for p53-induced apoptosis. ; RL Nature 389: (1997). RN [2] RP SEQUENCE FROM N.A. RA Jakobsson P.-J., Mancini J.A., Ford-Hutchinson A.W.; RT Human microsomal glutathione S-transferase 1-like 1 (MGST1L1). ; RL Submitted (OCT-1997) to the EMBL/GenBank/DDBJ databases. CC -!- SUBCELLULAR LOCATION: INTEGRAL MEMBRANE PROTEIN (POTENTIAL). CC -!- SIMILARITY: BELONGS TO THE MAPEG FAMILY. CC CC This SWISS-PROT entry is copyright. It is produced through a collaboration CC between the Swiss Institute of Bioinformatics and the EMBL outstation - CC the European Bioinformatics Institute. There are no restrictions on its CC use by non-profit institutions as long as its content is in no way CC modified and this statement is not removed. Usage by and for commercial CC entities requires a license agreement (See CC or send an to CC DR EMBL; AF010316; AAC ; -. DR EMBL; AF027740; AAB ; -. DR InterPro; IPR001129; -. DR Pfam; PF01124; MAPEG; 1. KW Transmembrane. FT TRANSMEM POTENTIAL. FT TRANSMEM POTENTIAL. FT CONFLICT G -> GG (IN REF. 1). SQ SEQUENCE 152 AA; MW; BF9B9ED81CA67A3D CRC64; MPAHSLVMSS PALPAFLLCS TLLVIKMYVV AIITGQVRLR KKAFANPEDA LRHGGPQYCR SDPDVERCLR AHRNDMETIY PFLFLGFVYS FLGPNPFVAW MHFLVFLVGR VAHTVAYLGK LRAPIRSVTY TLAQLPCASM ALQILWEAAR HL //.")
190
AAGENESEQAAGENESEQ ID B03071 standard; Protein; 594 AA. XX AC B03071; XX DT 10-OCT-2000 (first entry) XX DE Chimeric human GAD67/rat GAD65 glutamic acid decarboxylase, SEQ ID NO:2. XX KW Glutamic acid decarboxylase; chimeric protein; human GAD67; rat GAD65; XX OS Chimeric - Homo sapiens. OS Chimeric - Rattus sp. XX FH Key Location/Qualifiers FT Region 1..230 FT /note= "Human GAD67, residues 1-230" FT Misc-difference 144 FT /label= unknown -----------------------cut------------------------------- XX PN US6060593-A. XX PD 09-MAY-2000. XX PF 23-FEB-1998; 98US-0028148. XX PR 26-JAN-1996; 96US-0592696. XX PA (UYVA-) UNIV VANDERBILT. XX PI Powers AC; XX DR WPI; 2000-349703/30. DR N-PSDB; A52593. XX PT New nucleic acid encoding chimeric polypeptide comprising glutamic acid PT decarboxylase 67 and 65 proteins, useful for diagnosing and screening PT patients at the risk for developing insulin dependent diabetes mellitus XX PS Examples; Column 15-20; 16pp; English. XX CC This sequence represents a chimeric glutamic acid decarboxylase (GAD), CC comprising, N- to C-terminally, residues 1-230 of human GAD67, -----------------------------cut------------------------------XX SQ Sequence 594 AA; SQ 40 A; 30 R; 28 N; 32 D; 0 B; 13 C; 21 Q; 38 E; 0 Z; 43 G; 15 H; SQ 31 I; 57 L; 39 K; 19 M; 29 F; 20 P; 37 S; 36 T; 9 W; 20 Y; 35 V; SQ 2 Others; masstpsssa tssnagadpn ttnlrpttyd twcgvahgct rklglkicgf lqrtnsleek srlvsafker qssknllsce nsdrdarfrr tetdfsnlfa rdllpaknge eqtvqfllev vdillnyvrk tfdrstkvld fhhxhqlleg megfnlelsd hpesleqilv dcrdtlkygv dkclelaeyl yniiknregy emvfdgkpqh tnvcfwfvpp slrvlednee rmsrlskvap vikarmmeyg ttmvsyqplg dkvnffrmvi snpaathqdi dflieeierl gqdl //
 XX DE Chimeric human GAD67/rat GAD65 glutamic acid decarboxylase, SEQ ID NO:2. XX KW Glutamic acid decarboxylase; chimeric protein; human GAD67; rat GAD65; XX OS Chimeric - Homo sapiens. OS Chimeric - Rattus sp. XX FH Key Location/Qualifiers FT Region FT /note= Human GAD67, residues FT Misc-difference 144 FT /label= unknown cut XX PN US A. XX PD 09-MAY XX PF 23-FEB-1998; 98US XX PR 26-JAN-1996; 96US XX PA (UYVA-) UNIV VANDERBILT. XX PI Powers AC; XX DR WPI; /30. DR N-PSDB; A XX PT New nucleic acid encoding chimeric polypeptide comprising glutamic acid PT decarboxylase 67 and 65 proteins, useful for diagnosing and screening PT patients at the risk for developing insulin dependent diabetes mellitus XX PS Examples; Column 15-20; 16pp; English. XX CC This sequence represents a chimeric glutamic acid decarboxylase (GAD), CC comprising, N- to C-terminally, residues of human GAD67, cut XX SQ Sequence 594 AA; SQ 40 A; 30 R; 28 N; 32 D; 0 B; 13 C; 21 Q; 38 E; 0 Z; 43 G; 15 H; SQ 31 I; 57 L; 39 K; 19 M; 29 F; 20 P; 37 S; 36 T; 9 W; 20 Y; 35 V; SQ 2 Others; masstpsssa tssnagadpn ttnlrpttyd twcgvahgct rklglkicgf lqrtnsleek srlvsafker qssknllsce nsdrdarfrr tetdfsnlfa rdllpaknge eqtvqfllev vdillnyvrk tfdrstkvld fhhxhqlleg megfnlelsd hpesleqilv dcrdtlkygv dkclelaeyl yniiknregy emvfdgkpqh tnvcfwfvpp slrvlednee rmsrlskvap vikarmmeyg ttmvsyqplg dkvnffrmvi snpaathqdi dflieeierl gqdl //.")
191
InterProInterPro

192
XML (InterPro)
")
193
PrositeProsite ID CNMP_BINDING_1; PATTERN. AC PS00888; DT OCT-1993 (CREATED); NOV-1997 (DATA UPDATE); JUL-1998 (INFO UPDATE). DE Cyclic nucleotide-binding domain signature 1. PA [LIVM]-[VIC]-x(2)-G-[DENQTA]-x-[GAC]-x(2)-[LIVMFY](4)-x(2)-G. NR /RELEASE=38,80000; NR /TOTAL=77(52); /POSITIVE=77(52); /UNKNOWN=0(0); /FALSE_POS=0(0); NR /FALSE_NEG=0; /PARTIAL=2; CC /TAXO-RANGE=??EP?; /MAX-REPEAT=2; DR Q00194, CNG1_BOVIN, T; Q28279, CNG1_CANFA, T; Q90805, CNG1_CHICK, T; DR P29973, CNG1_HUMAN, T; P29974, CNG1_MOUSE, T; Q62927, CNG1_RAT, T; DR Q03041, CNG2_BOVIN, T; Q16280, CNG2_HUMAN, T; Q62398, CNG2_MOUSE, T; DR Q28718, CNG2_RABIT, T; Q00195, CNG2_RAT, T; Q29441, CNG3_BOVIN, T; DR Q90980, CNG3_CHICK, T; Q16281, CNG3_HUMAN, T; Q28181, CNG4_BOVIN, T; DR Q14028, CNG4_HUMAN, T; Q64359, CNGX_RAT, T; Q24278, CNG_DROME, T; DR P55934, CNG_ICTPU, T; P03020, CRP_ECOLI, T; P29281, CRP_HAEIN, T; DR P06170, CRP_SALTY, T; P31320, KAPR_BLAEM, T; Q03042, KGP1_DROME, T; DR P32023, KGP3_DROME, T; Q03611, TAX4_CAEEL, T; P55222, VFR_PSEAE, T; DR P00514, KAP0_BOVIN, T; P10644, KAP0_HUMAN, T; P07802, KAP0_PIG, T; DR P09456, KAP0_RAT, T; P31321, KAP1_HUMAN, T; P12849, KAP1_MOUSE, T; DR P81377, KAP1_RAT, T; P00515, KAP2_BOVIN, T; P13861, KAP2_HUMAN, T; DR P12367, KAP2_MOUSE, T; P12368, KAP2_RAT, T; P31322, KAP3_BOVIN, T; DR P31323, KAP3_HUMAN, T; P12369, KAP3_RAT, T; P31319, KAPR_APLCA, T; DR P30625, KAPR_CAEEL, T; P05987, KAPR_DICDI, T; P16905, KAPR_DROME, T; DR P36600, KAPR_SCHPO, T; P49605, KAPR_USTMA, T; P07278, KAPR_YEAST, T; DR Q03043, KGP2_DROME, T; P00516, KGPA_BOVIN, T; P21136, KGPB_BOVIN, T; DR P14619, KGPB_HUMAN, T; DR P05207, KAP2_PIG, P; P31324, KAP3_MOUSE, P; 3D 2GAP; 3GAP; 1CGP; 2CGP; 1BER; 1RUN; 1RUO; 1APK; 1BPK; 1RGS; 2APK; 2BPK; 3D 1R2A; DO PDOC00691; //
; NOV-1997 (DATA UPDATE); JUL-1998 (INFO UPDATE). DE Cyclic nucleotide-binding domain signature 1. PA [LIVM]-[VIC]-x(2)-G-[DENQTA]-x-[GAC]-x(2)-[LIVMFY](4)-x(2)-G. NR /RELEASE=38,80000; NR /TOTAL=77(52); /POSITIVE=77(52); /UNKNOWN=0(0); /FALSE_POS=0(0); NR /FALSE_NEG=0; /PARTIAL=2; CC /TAXO-RANGE= EP ; /MAX-REPEAT=2; DR Q00194, CNG1_BOVIN, T; Q28279, CNG1_CANFA, T; Q90805, CNG1_CHICK, T; DR P29973, CNG1_HUMAN, T; P29974, CNG1_MOUSE, T; Q62927, CNG1_RAT, T; DR Q03041, CNG2_BOVIN, T; Q16280, CNG2_HUMAN, T; Q62398, CNG2_MOUSE, T; DR Q28718, CNG2_RABIT, T; Q00195, CNG2_RAT, T; Q29441, CNG3_BOVIN, T; DR Q90980, CNG3_CHICK, T; Q16281, CNG3_HUMAN, T; Q28181, CNG4_BOVIN, T; DR Q14028, CNG4_HUMAN, T; Q64359, CNGX_RAT, T; Q24278, CNG_DROME, T; DR P55934, CNG_ICTPU, T; P03020, CRP_ECOLI, T; P29281, CRP_HAEIN, T; DR P06170, CRP_SALTY, T; P31320, KAPR_BLAEM, T; Q03042, KGP1_DROME, T; DR P32023, KGP3_DROME, T; Q03611, TAX4_CAEEL, T; P55222, VFR_PSEAE, T; DR P00514, KAP0_BOVIN, T; P10644, KAP0_HUMAN, T; P07802, KAP0_PIG, T; DR P09456, KAP0_RAT, T; P31321, KAP1_HUMAN, T; P12849, KAP1_MOUSE, T; DR P81377, KAP1_RAT, T; P00515, KAP2_BOVIN, T; P13861, KAP2_HUMAN, T; DR P12367, KAP2_MOUSE, T; P12368, KAP2_RAT, T; P31322, KAP3_BOVIN, T; DR P31323, KAP3_HUMAN, T; P12369, KAP3_RAT, T; P31319, KAPR_APLCA, T; DR P30625, KAPR_CAEEL, T; P05987, KAPR_DICDI, T; P16905, KAPR_DROME, T; DR P36600, KAPR_SCHPO, T; P49605, KAPR_USTMA, T; P07278, KAPR_YEAST, T; DR Q03043, KGP2_DROME, T; P00516, KGPA_BOVIN, T; P21136, KGPB_BOVIN, T; DR P14619, KGPB_HUMAN, T; DR P05207, KAP2_PIG, P; P31324, KAP3_MOUSE, P; 3D 2GAP; 3GAP; 1CGP; 2CGP; 1BER; 1RUN; 1RUO; 1APK; 1BPK; 1RGS; 2APK; 2BPK; 3D 1R2A; DO PDOC00691; //.")
194
BrendaBrenda #1# Rat #2# Rabbit #3# Mouse #4# Guinea pig #5# Hamster #6# Dog #7# Cat SYSTEMATIC NAME (+,-)-trans-Acenaphthene-1,2-diol:NADP+ oxidoreductase RECOMMENDED NAME trans-Acenaphthene-1,2-diol dehydrogenase SYNONYMS trans-1,2-Acenaphthenediol dehydrogenase Dehydrogenase, trans-acenaphthylene-1,2-diol CAS REGISTRY NUMBER 51901-21-4 REACTION (+,-)-trans-Acenaphthene-1,2-diol + NADP+ = acenaphthenequinone + NADPH REACTION TYPE Redox reaction SUBSTRATES/PRODUCTS S: 1-Acenaphthenol + NADP+ #1-7# P: 1-Acenaphthenone + NADPH |i.e. 2H-acenaphthylene-1-one|| S: trans-1,2-Dihydronaphthalene-1,2-diol + NADP+ #1-7# P: 1,2-Naphthoquinone + NADPH S: (-)trans-Acenaphthene-1,2-diol + NADP+ #1-7# |inactive with (+)-form, #1-7# || P: Acenaphthenequinone + NADPH |i.e. acenaphthylene-1,2-dione|| SPECIFIC ACTIVITY -999 #1-7# COFACTORS/PROSTHETIC GROUPS Ethanol #1# |activation|| NADP+ #1# |inactive with NAD+|| METALS/IONS Mg2+ #1# |activation|| INHIBITORS (+)-trans-Acenaphthene-1,2-diol #1# Catechol #1# Hg2+ #1# KCN #1# NADPH #1# p-Chloromercuribenzoate #1# SOURCE TISSUE Liver #1-7# LOCALIZATION Cytosol #1-7# PURIFICATION #1# REFERENCES Hopkins, R.P., Drummond, E.C., Callaghan, P.: :: Biochem. Soc. Trans., 1; 989- 991 (1973) Drummond, E.C, Callaghan, P., Hopkins, R.P.: Metabolic dehydrogenation of cis- and trans-acenaphthene-1,2-diol:: Xenobiotica, 2; 529-538 (1972)
trans-Acenaphthene-1,2-diol + NADP+ #1-7# |inactive with (+)-form, #1-7# || P: Acenaphthenequinone + NADPH |i.e. acenaphthylene-1,2-dione|| SPECIFIC ACTIVITY -999 #1-7# COFACTORS/PROSTHETIC GROUPS Ethanol #1# |activation|| NADP+ #1# |inactive with NAD+|| METALS/IONS Mg2+ #1# |activation|| INHIBITORS (+)-trans-Acenaphthene-1,2-diol #1# Catechol #1# Hg2+ #1# KCN #1# NADPH #1# p-Chloromercuribenzoate #1# SOURCE TISSUE Liver #1-7# LOCALIZATION Cytosol #1-7# PURIFICATION #1# REFERENCES Hopkins, R.P., Drummond, E.C., Callaghan, P.: :: Biochem. Soc. Trans., 1; (1973) Drummond, E.C, Callaghan, P., Hopkins, R.P.: Metabolic dehydrogenation of cis- and trans-acenaphthene-1,2-diol:: Xenobiotica, 2; (1972).")
195
PATHWAYPATHWAY

196
MEDLINEMEDLINE

197
Remote use of SRS SRS can be used as a network based cross-reference tool: –http://srs.ebi.ac.uk/cgi-bin/wgetz?+e+[embl-id:hscfos] –http://www.ebi.ac.uk/cgi-bin/emblfetch?hscfos Typically, it is used to cross-reference results from similarity and homology and function prediction searches (I.e. fasta, blast, MPsrch, InterProscan etc.)
![Remote use of SRS SRS can be used as a network based cross-reference tool: – +e+[embl-id:hscfos] – hscfos Typically, it is used to cross-reference results from similarity and homology and function prediction searches (I.e.](http://images.slideplayer.com/15/4811415/slides/slide_197.jpg "fasta, blast, MPsrch, InterProscan etc.).")
198
New InterProScan

199
Remote linking to SRS Permits free and easy access to remote data. :-) Not necessary to maintain too many databanks locally. :-) It is network availability dependant :-( It is not maintenance intensive. :-)
 Not necessary to maintain too many databanks locally. :-) It is network availability dependant :-( It is not maintenance intensive. :-).")
200
EBI’s SRS set-up 4xCompaq ES40 with 4 800Mhz alpha CPUs, 4Gb of RAM and 2.5 Tb of SAN storage. The 4 hosts are configure as a TruCluster. Indexing is carefully scheduled using Platform’s LSF queuing system.

201
Databanks under SRS at EBI Currently more than 200 libraries and 154 tools publicly visible. –Databank total is 180 with many awaiting ‘publishing’. We are aiming at reducing the number of databases available at the EBI by creating virtual libraries: –EMBLRel.+EMBLNEW=EMBL –swissprot+(swissnew- delta)+sptrembl+tremblnew=UniProt
+sptrembl+tremblnew=UniProt.")
202
ConstraintsConstraints Databank must have informative value to enhance the system. Fasta formatted databases are implicitly avoided. Linking (hard and relative links) are encouraged.
 are encouraged..")
203
Database Search Tools

205
KEGG Metabolic pathways Regulatory pathways Disease Catalogs, Cell Catalogs Molecule Catalogs; compounds and enzymes Gene Catalogs Genome Maps Gene Expression Profiles Computational Tools Links to other pathway and compound sites Keywords: metabolic pathways / proteomics / metabolomics GenomeNet www.genome.ad.jp

206
GenomeNet / KEGG Metabolic Pathways Graphical pathway maps and ortholog group tables Maps are fully interactive Regulatory Pathways GenomeNet www.genome.ad.jp

207
GenomeNet / KEGG Gene Expression Profiles Still preliminary character Clickable signals allow identification of enzyme GenomeNet www.genome.ad.jp

208
High quality search engine for biologists Many applications Largest collection of biology links on the WWW ( few outdated) Keywords: Proteins / proteomics / applications ExPASy http://www.expasy.ch ExPASy http://www.expasy.ch
 Keywords: Proteins / proteomics / applications ExPASy ExPASy")
209
ExPASy http://www.expasy.ch ExPASy http://www.expasy.ch

210
Software for 2D analysis Swiss-PdbViewer is an application that provides a user friendly interface allowing to analyse several proteins at the same time. SWISS-MODEL, An Automated Comparative Protein Modelling Server ExPASy http://www.expasy.ch ExPASy http://www.expasy.ch

211
It goes to the library, you go to the pub. Automatic system which searches PubMed or other databases as often as you want with your keywords or sequences Similar systems exist, links are indicated on the PubCrawler homepage Pubcrawler http://www.gen/tcd.ie/pubcrawler Pubcrawler http://www.gen/tcd.ie/pubcrawler

212
Databases of proteins (Protfam), RNAs, mitochondrial sequences Genome projects of human, yeast and Arabidopsis Pathways, Proteomics Yeast ORFs and genes Small but comprehensive link list An alert utility sends you once per week, via email, new database entries related to your field of study. ORPHEUS is a software system for gene prediction in complete bacterial genomes and large genomic fragments. Keyword: Proteins and more... MIPS http://www.mips.biochem.mpg.de MIPS http://www.mips.biochem.mpg.de

213
What to take home Databases are a collection of data –Need to access and maintain easily and flexibly Biological information is vast and sometimes very redundant Distributed databases bring it all together with quality controls, cross-referencing and standardization Computers can only create data, they do not give answers Review-suggestion: “Integrating biological databases”, Stein, Nature 2003

214
ResourcesResources W W W: –http://nar.oupjournals.org/content/vol30/issue1/ –http://nar.oupjournals.org/content/vol31/issue1/ –http://www.ncbi.nlm.nih.gov/HTGS/ –http://www.ncbi.nlm.nih.gov/dbEST/ –http://www.ncbi.nlm.nih.gov/Genbank/wgs.html –http://www.ncbi.nlm.nih.gov/dbSTS/ –http://www.ncbi.nlm.nih.gov/dbGSS/ –http://www.ncbi.nlm.nih.gov/genome/guide/

215
ResourcesResources W W W: –http://www.ncbi.nlm.nih.gov –http://www.ddbj.nig.ac.jp/ –http://www.ebi.ac.uk/ –http://www.ncbi.nlm.nih.gov/Genbank/GenbankOverview.html –http://www.ebi.ac.uk/embl/ –http://www.pir.uniprot.org/ –http://www.expasy.ch/sprot/ –http://www.rcsb.org/pdb/ –http://www.ncbi.nlm.nih.gov/Genbank/ (submission info) –http://genome-www.stanford.edu/Saccharomyces/
 –")
216
ResourcesResources W W W: –http://bioinformatics.ubc.ca –http://bioinformatics.ca –http://pubcrawler.gen.tcd.ie/ –http://www.tigr.org/ –http://www.tigr.org/tdb/tgi/plant.shtml –http://www.ncbi.nlm.nih.gov –http://www.ddbj.nig.ac.jp/ –http://www.ebi.ac.uk/ –http://www.ncbi.nlm.nih.gov/Genbank/GenbankOverview.html –http://www.ebi.ac.uk/embl/ –http://www.pir.uniprot.org/ –http://www.rcsb.org/pdb/ –http://genome-www.stanford.edu/Saccharomyces/

217
ResourcesResources W W W: –http://nar.oupjournals.org/content/vol32/suppl_1/ –http://nar.oupjournals.org/content/vol33/suppl_1/ –http://www.ncbi.nlm.nih.gov/HTGS/ –http://www.ncbi.nlm.nih.gov/dbEST/ –http://www.ncbi.nlm.nih.gov/Genbank/wgs.html –http://www.ncbi.nlm.nih.gov/dbSTS/ –http://www.ncbi.nlm.nih.gov/dbGSS/ –http://www.ncbi.nlm.nih.gov/genome/guide/human

218
Bio-databases: A short word on problems Even today we face some key limitations –There is no standard format Every database or program has its own format –There is no standard nomenclature Every database has its own names –Data is not fully optimized Some datasets have missing information without indications of it –Data errors Data is sometimes of poor quality, erroneous, misspelled Error propagation resulting from computer annotation

Similar presentations












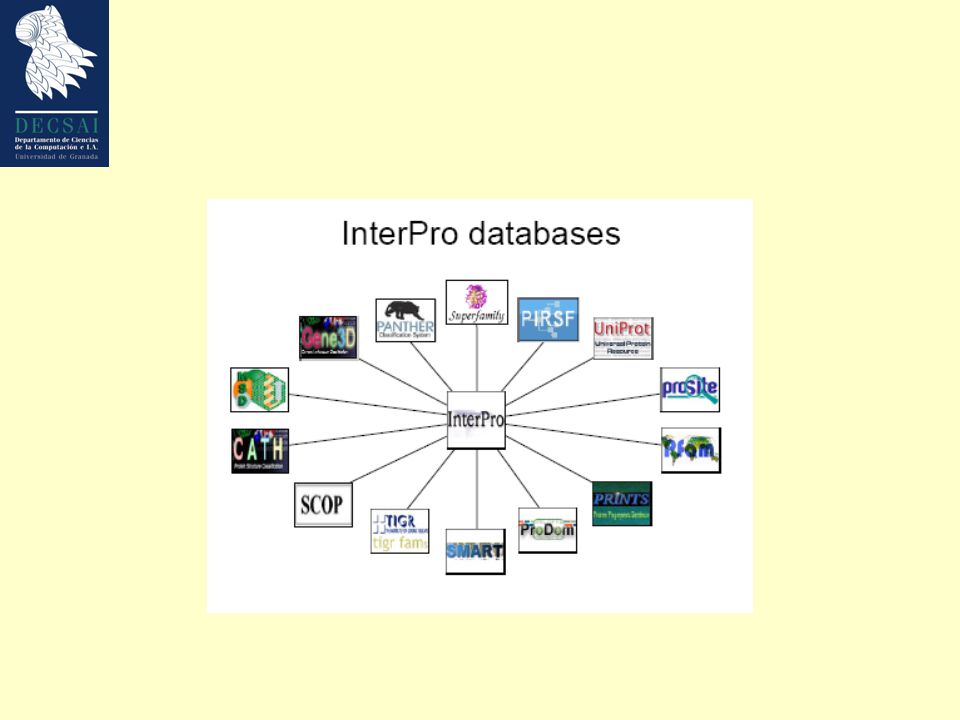













 Sequence Information Lecture 7.>")
 a primary resource for molecular biology information www.ncbi.nih.gov Database Resources.>")














